Revisiting the Role of Language Priors in Vision-Language Models
2306.01879
0
0
💬
Abstract
Vision-language models (VLMs) are impactful in part because they can be applied to a variety of visual understanding tasks in a zero-shot fashion, without any fine-tuning. We study $textit{generative VLMs}$ that are trained for next-word generation given an image. We explore their zero-shot performance on the illustrative task of image-text retrieval across 8 popular vision-language benchmarks. Our first observation is that they can be repurposed for discriminative tasks (such as image-text retrieval) by simply computing the match score of generating a particular text string given an image. We call this probabilistic score the $textit{Visual Generative Pre-Training Score}$ (VisualGPTScore). While the VisualGPTScore produces near-perfect accuracy on some retrieval benchmarks, it yields poor accuracy on others. We analyze this behavior through a probabilistic lens, pointing out that some benchmarks inadvertently capture unnatural language distributions by creating adversarial but unlikely text captions. In fact, we demonstrate that even a blind language model that ignores any image evidence can sometimes outperform all prior art, reminiscent of similar challenges faced by the visual-question answering (VQA) community many years ago. We derive a probabilistic post-processing scheme that controls for the amount of linguistic bias in generative VLMs at test time without having to retrain or fine-tune the model. We show that the VisualGPTScore, when appropriately debiased, is a strong zero-shot baseline for vision-language understanding, oftentimes producing state-of-the-art accuracy.
Create account to get full access
Overview
- Vision-language models (VLMs) can be applied to various visual understanding tasks without any additional training.
- This paper examines generative VLMs that are trained to generate text given an image.
- The researchers explore the zero-shot performance of these models on the task of image-text retrieval across 8 popular benchmarks.
Plain English Explanation
Vision-language models (VLMs) are a type of artificial intelligence system that can understand and work with both images and text. One of the powerful capabilities of these models is that they can be applied to a variety of visual understanding tasks without needing to be specifically trained for each one. This is known as "zero-shot" performance.
In this paper, the researchers focus on a specific type of VLM called a generative VLM. These models are trained to generate text, such as captions, based on an input image. The researchers explore how well these generative VLMs can perform on the task of image-text retrieval - where the goal is to find the text that best matches a given image.
The researchers look at the performance of these generative VLMs on 8 different image-text retrieval benchmarks, which are standard datasets used to evaluate these types of systems. They find that the generative VLMs can achieve near-perfect accuracy on some of the benchmarks, but struggle on others.
The researchers analyze this behavior and discover that some of the benchmarks inadvertently contain "adversarial" text captions that are very unlikely to occur naturally. In fact, they find that even a language model that completely ignores the image can sometimes outperform all previous approaches on these benchmarks.
To address this issue, the researchers develop a probabilistic post-processing scheme that can adjust the output of the generative VLMs to account for this linguistic bias in the benchmarks. When this debiasing technique is applied, the generative VLMs become a strong zero-shot baseline, often achieving state-of-the-art performance on the image-text retrieval tasks.
Technical Explanation
The researchers in this paper examine generative vision-language models (VLMs) - models that are trained to generate text, such as captions, given an input image. They explore the zero-shot performance of these models on the task of image-text retrieval, where the goal is to find the text that best matches a given image.
The researchers first observe that these generative VLMs can be repurposed for discriminative tasks like image-text retrieval by computing a probabilistic score called the Visual Generative Pre-Training Score (VisualGPTScore) - the likelihood of generating a particular text string given an image.
While the VisualGPTScore produces near-perfect accuracy on some retrieval benchmarks, the researchers find that it performs poorly on others. They analyze this behavior through a probabilistic lens, pointing out that some benchmarks inadvertently capture unnatural language distributions by creating "adversarial" but unlikely text captions.
In fact, the researchers demonstrate that even a blind language model that ignores any image evidence can sometimes outperform all prior art on these benchmarks, reminiscent of similar challenges faced by the visual-question answering (VQA) community in the past.
To address this issue, the researchers derive a probabilistic post-processing scheme that can control for the amount of linguistic bias in generative VLMs at test time, without having to retrain or fine-tune the model. They show that the VisualGPTScore, when appropriately debiased, is a strong zero-shot baseline for vision-language understanding, often producing state-of-the-art accuracy on the image-text retrieval benchmarks.
Critical Analysis
The researchers in this paper raise important concerns about the design and evaluation of vision-language benchmarks, which can inadvertently capture linguistic biases that undermine the true capabilities of these models.
One limitation of the paper is that it only examines generative VLMs, and does not explore the behavior of discriminative VLMs (e.g., VITAMIN-C, Semantically Prompted Language Models) on these benchmarks. It would be valuable to see how the researchers' debiasing approach applies to a wider range of VLM architectures.
Additionally, the paper focuses on image-text retrieval tasks, but the researchers acknowledge that the linguistic biases they identify may be present in other vision-language tasks as well, such as visual question answering. Further investigation into the prevalence and impact of these biases across a broader range of vision-language benchmarks would help to better understand the limitations of current evaluation practices.
Overall, this paper makes an important contribution by highlighting the need for more careful design and analysis of vision-language benchmarks, in order to ensure that they accurately reflect the true capabilities of these powerful models and drive the field forward in a meaningful way.
Conclusion
This paper examines the zero-shot performance of generative vision-language models (VLMs) on the task of image-text retrieval, across a range of popular benchmarks. The researchers find that while these models can achieve near-perfect accuracy on some benchmarks, they struggle on others due to the presence of linguistic biases in the dataset.
By developing a probabilistic post-processing scheme to debias the model outputs, the researchers show that generative VLMs can serve as a strong zero-shot baseline for vision-language understanding, often matching or exceeding the state-of-the-art. This work highlights the importance of carefully designing and analyzing vision-language benchmarks to ensure they accurately reflect the true capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
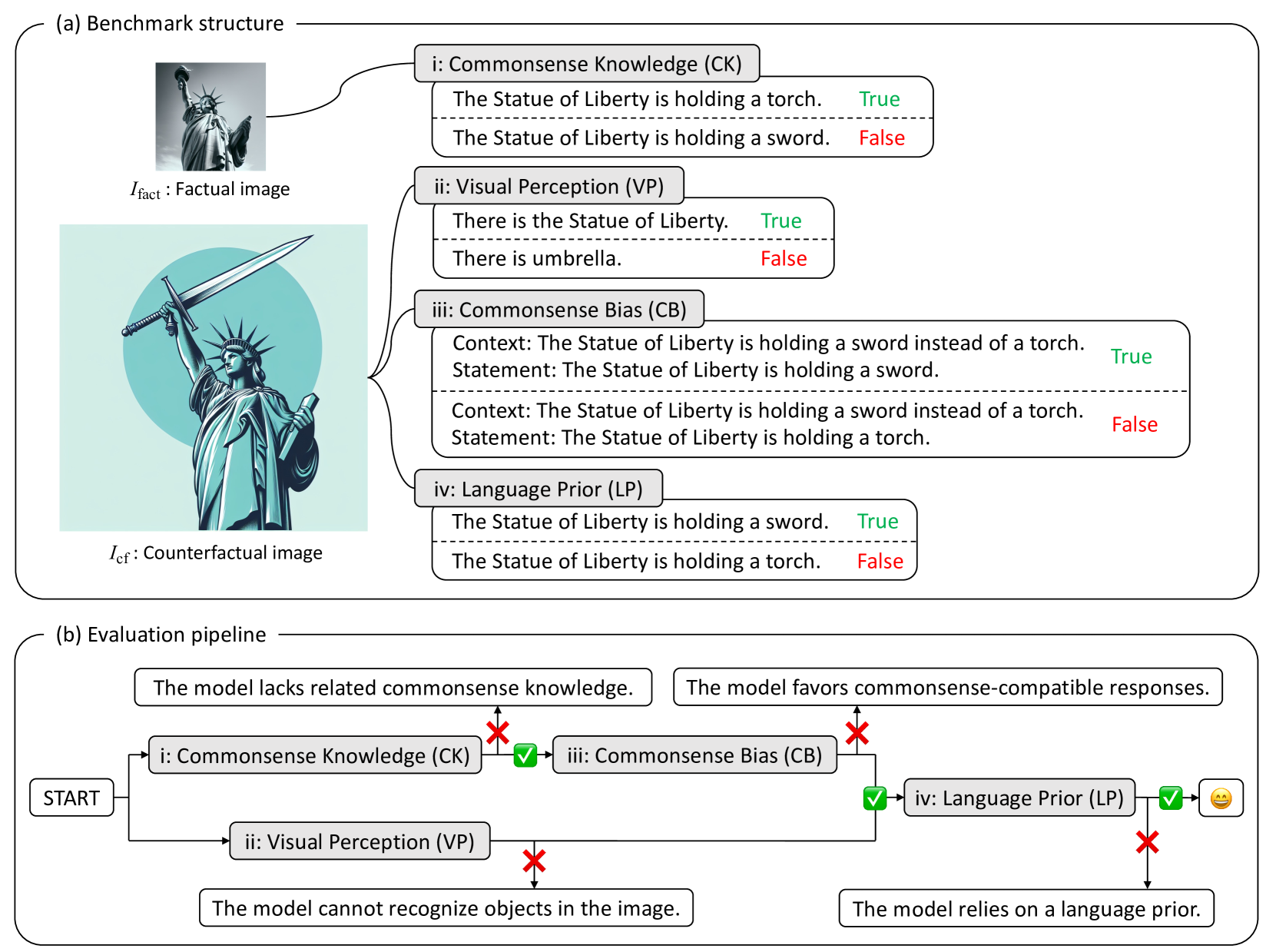
VLind-Bench: Measuring Language Priors in Large Vision-Language Models
Kang-il Lee, Minbeom Kim, Minsung Kim, Dongryeol Lee, Hyukhun Koh, Kyomin Jung
0
0
Large Vision-Language Models (LVLMs) have demonstrated outstanding performance across various multimodal tasks. However, they suffer from a problem known as language prior, where responses are generated based solely on textual patterns while disregarding image information. Addressing the issue of language prior is crucial, as it can lead to undesirable biases or hallucinations when dealing with images that are out of training distribution. Despite its importance, current methods for accurately measuring language priors in LVLMs are poorly studied. Although existing benchmarks based on counterfactual or out-of-distribution images can partially be used to measure language priors, they fail to disentangle language priors from other confounding factors. To this end, we propose a new benchmark called VLind-Bench, which is the first benchmark specifically designed to measure the language priors, or blindness, of LVLMs. It not only includes tests on counterfactual images to assess language priors but also involves a series of tests to evaluate more basic capabilities such as commonsense knowledge, visual perception, and commonsense biases. For each instance in our benchmark, we ensure that all these basic tests are passed before evaluating the language priors, thereby minimizing the influence of other factors on the assessment. The evaluation and analysis of recent LVLMs in our benchmark reveal that almost all models exhibit a significant reliance on language priors, presenting a strong challenge in the field.
6/19/2024

An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
0
0
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
5/28/2024

The Neglected Tails in Vision-Language Models
Shubham Parashar, Zhiqiu Lin, Tian Liu, Xiangjue Dong, Yanan Li, Deva Ramanan, James Caverlee, Shu Kong
0
0
Vision-language models (VLMs) excel in zero-shot recognition but their performance varies greatly across different visual concepts. For example, although CLIP achieves impressive accuracy on ImageNet (60-80%), its performance drops below 10% for more than ten concepts like night snake, presumably due to their limited presence in the pretraining data. However, measuring the frequency of concepts in VLMs' large-scale datasets is challenging. We address this by using large language models (LLMs) to count the number of pretraining texts that contain synonyms of these concepts. Our analysis confirms that popular datasets, such as LAION, exhibit a long-tailed concept distribution, yielding biased performance in VLMs. We also find that downstream applications of VLMs, including visual chatbots (e.g., GPT-4V) and text-to-image models (e.g., Stable Diffusion), often fail to recognize or generate images of rare concepts identified by our method. To mitigate the imbalanced performance of zero-shot VLMs, we propose REtrieval-Augmented Learning (REAL). First, instead of prompting VLMs using the original class names, REAL uses their most frequent synonyms found in pretraining texts. This simple change already outperforms costly human-engineered and LLM-enriched prompts over nine benchmark datasets. Second, REAL trains a linear classifier on a small yet balanced set of pretraining data retrieved using concept synonyms. REAL surpasses the previous zero-shot SOTA, using 400x less storage and 10,000x less training time!
5/24/2024

Benchmarking Zero-Shot Recognition with Vision-Language Models: Challenges on Granularity and Specificity
Zhenlin Xu, Yi Zhu, Tiffany Deng, Abhay Mittal, Yanbei Chen, Manchen Wang, Paolo Favaro, Joseph Tighe, Davide Modolo
0
0
This paper presents novel benchmarks for evaluating vision-language models (VLMs) in zero-shot recognition, focusing on granularity and specificity. Although VLMs excel in tasks like image captioning, they face challenges in open-world settings. Our benchmarks test VLMs' consistency in understanding concepts across semantic granularity levels and their response to varying text specificity. Findings show that VLMs favor moderately fine-grained concepts and struggle with specificity, often misjudging texts that differ from their training data. Extensive evaluations reveal limitations in current VLMs, particularly in distinguishing between correct and subtly incorrect descriptions. While fine-tuning offers some improvements, it doesn't fully address these issues, highlighting the need for VLMs with enhanced generalization capabilities for real-world applications. This study provides insights into VLM limitations and suggests directions for developing more robust models.
6/19/2024