Sampling the Swadesh List to Identify Similar Languages with Tree Spaces

0
🎯
Sign in to get full access
Overview
- This research paper explores the use of data analysis and tree-like structures to study the relationships between different languages, particularly those that use the Latin script.
- The authors are interested in the ancestry of the English language and the Latin alphabet, as well as the broader connections between modern languages and their Proto-Indo-European roots.
- The paper introduces a unique mathematical model, the "3-spider," which can represent the tree-like structures of language clustering and relationships.
Plain English Explanation
Language is a fundamental aspect of human interaction and communication. Studying language quantitatively has become more common in recent years, with the development of fields like quantitative comparative linguistics and lexicostatistics.
In this paper, the authors are particularly interested in the ancestry of the English language and the Latin alphabet. They use a mathematical model called the "3-spider" to represent the tree-like structures of language relationships, based on the Proto-Indo-European language tree.
The 3-spider is a simple geometric shape made up of three rays (or "legs") that are connected at a single point. This shape can be used to visualize the clustering and relationships between different languages that use the Latin script. The authors use a clustering method called "single linkage" to build these language trees based on the distances between samples from different languages.
By analyzing the properties of these language trees, the researchers can gain insights into the ancestry and relationships between the languages. For example, if the "mean" or center point of the tree is "non-sticky," it may indicate that one language has a different ancestor than the other two. If the mean is "sticky," it suggests the languages share a common ancestor or have independent ancestries.
Technical Explanation
The paper presents a data-driven approach to studying the relationships between different languages, particularly those that use the Latin script. The authors leverage computational techniques to analyze the ancestry and connections between modern languages and their Proto-Indo-European roots.
The core of the research involves the use of a unique mathematical model called the "3-spider." This shape, which is a union of three rays with their endpoints glued at a single point, can be used to represent the tree-like structures that emerge when clustering languages based on their similarities and differences.
The researchers use a single linkage clustering method to build these language trees, which groups languages together based on the distances between samples from each language. By analyzing the properties of the resulting tree structures, the authors can gain insights into the ancestry and relationships between the languages.
Specifically, the researchers examine the "barycenter" or mean of the tree, which represents the average of the three languages being analyzed. If the mean exhibits "non-sticky" properties, it may suggest that one of the languages has a different ancestral origin than the other two. Conversely, a "sticky" mean indicates that the languages either share a common ancestor or have completely independent ancestries.
The paper presents some initial results using this 3-spider model and discusses the potential implications of these findings for our understanding of language evolution and relationships.
Critical Analysis
The research presented in this paper offers a novel and quantitative approach to studying language relationships and ancestry. By leveraging computational techniques and a unique geometric model, the authors are able to gain insights into the connections between modern languages and their historical roots.
One potential limitation of the research is the reliance on data from only languages that use the Latin script. While this allows for a more focused analysis, it may limit the broader applicability of the findings. Expanding the study to include languages that use other writing systems could provide a more comprehensive understanding of global language relationships.
Additionally, the authors mention that their initial results have found both "non-sticky" and "sticky" sample means, which can lead to different interpretations about language ancestry. While this is an interesting finding, further research may be needed to fully understand the implications and potential sources of these divergent patterns.
It would also be valuable to see the researchers explore the sensitivity of their model to factors such as language sample size, data quality, and the choice of clustering algorithm. Assessing the robustness of the 3-spider model under different conditions could strengthen the reliability and generalizability of the findings.
Overall, this paper presents a promising approach to the study of linguistic diversity and cross-lingual transfer that could have important implications for our understanding of language evolution and the relationships between different language families.
Conclusion
This research paper introduces a novel, data-driven approach to studying the relationships and ancestry of different languages, particularly those that use the Latin script. By leveraging a unique mathematical model called the "3-spider" and employing computational techniques, the authors are able to gain insights into the connections between modern languages and their Proto-Indo-European roots.
The findings presented in the paper, including the identification of both "non-sticky" and "sticky" sample means, suggest that this approach has the potential to provide valuable information about the evolutionary paths and ancestral relationships of various languages. While the current study is focused on languages using the Latin script, expanding the research to include a broader range of writing systems could lead to a more comprehensive understanding of global language diversity and its origins.
Overall, this paper represents an important contribution to the field of quantitative comparative linguistics and computational approaches to language analysis. The insights gained from this research could have significant implications for our understanding of human language evolution and the development of more effective multilingual natural language processing systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
0
Sampling the Swadesh List to Identify Similar Languages with Tree Spaces
Garett Ordway, Vic Patrangenaru
Communication plays a vital role in human interaction. Studying language is a worthwhile task and more recently has become quantitative in nature with developments of fields like quantitative comparative linguistics and lexicostatistics. With respect to the authors own native languages, the ancestry of the English language and the Latin alphabet are of the primary interest. The Indo-European Tree traces many modern languages back to the Proto-Indo-European root. Swadesh's cognates played a large role in developing that historical perspective where some of the primary branches are Germanic, Celtic, Italic, and Balto-Slavic. This paper will use data analysis on open books where the simplest singular space is the 3-spider - a union T3 of three rays with their endpoints glued at a point 0 - which can represent these tree spaces for language clustering. These trees are built using a single linkage method for clustering based on distances between samples from languages which use the Latin Script. Taking three languages at a time, the barycenter is determined. Some initial results have found both non-sticky and sticky sample means. If the mean exhibits non-sticky properties, then one language may come from a different ancestor than the other two. If the mean is considered sticky, then the languages may share a common ancestor or all languages may have different ancestry.
Read more5/13/2024
📈
0
Are Sounds Sound for Phylogenetic Reconstruction?
Luise Hauser, Gerhard Jager, Taraka Rama, Johann-Mattis List, Alexandros Stamatakis
In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.
Read more5/15/2024
🏋️
0
The correlation between nativelike selection and prototypicality: a multilingual onomasiological case study using semantic embedding
Huasheng Zhang
In native speakers' lexical choices, a concept can be more readily expressed by one expression over another grammatical one, a phenomenon known as nativelike selection (NLS). In previous research, arbitrary chunks such as collocations have been considered crucial for this phenomenon. However, this study examines the possibility of analyzing the semantic motivation and deducibility behind some NLSs by exploring the correlation between NLS and prototypicality, specifically the onomasiological hypothesis of Grondelaers and Geeraerts (2003, Towards a pragmatic model of cognitive onomasiology. In Hubert Cuyckens, Ren'e Dirven & John R. Taylor (eds.), Cognitive approaches to lexical semantics, 67-92. Berlin: De Gruyter Mouton). They hypothesized that [a] referent is more readily named by a lexical item if it is a salient member of the category denoted by that item. To provide a preliminary investigation of this important but rarely explored phenomenon, a series of innovative methods and procedures, including the use of semantic embedding and interlingual comparisons, is designed. Specifically, potential NLSs are efficiently discovered through an automatic exploratory analysis using topic modeling techniques, and then confirmed by manual inspection through frame semantics. Finally, to account for the NLS in question, cluster analysis and behavioral profile analysis are conducted to uncover a language-specific prototype for the Chinese verb shang 'harm', providing supporting evidence for the correlation between NLS and prototypicality.
Read more5/24/2024
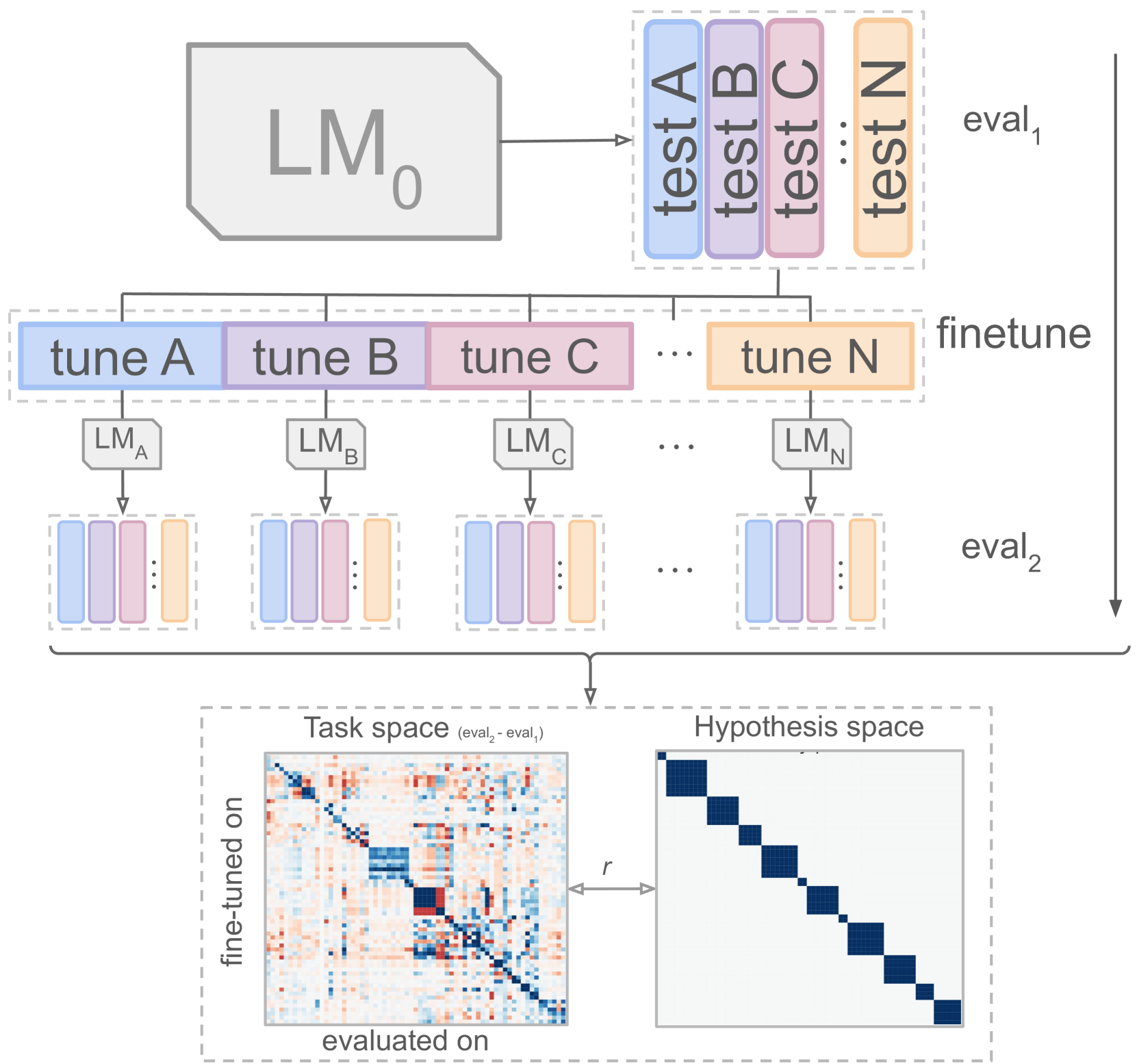
0
Interpretability of Language Models via Task Spaces
Lucas Weber, Jaap Jumelet, Elia Bruni, Dieuwke Hupkes
The usual way to interpret language models (LMs) is to test their performance on different benchmarks and subsequently infer their internal processes. In this paper, we present an alternative approach, concentrating on the quality of LM processing, with a focus on their language abilities. To this end, we construct 'linguistic task spaces' -- representations of an LM's language conceptualisation -- that shed light on the connections LMs draw between language phenomena. Task spaces are based on the interactions of the learning signals from different linguistic phenomena, which we assess via a method we call 'similarity probing'. To disentangle the learning signals of linguistic phenomena, we further introduce a method called 'fine-tuning via gradient differentials' (FTGD). We apply our methods to language models of three different scales and find that larger models generalise better to overarching general concepts for linguistic tasks, making better use of their shared structure. Further, the distributedness of linguistic processing increases with pre-training through increased parameter sharing between related linguistic tasks. The overall generalisation patterns are mostly stable throughout training and not marked by incisive stages, potentially explaining the lack of successful curriculum strategies for LMs.
Read more6/11/2024