A Simple Latent Diffusion Approach for Panoptic Segmentation and Mask Inpainting

0

Sign in to get full access
Overview
- This paper presents a simple latent diffusion approach for panoptic segmentation and mask inpainting tasks.
- The method leverages diffusion models to jointly learn instance segmentation and inpainting in a single framework.
- The approach is shown to achieve competitive performance on panoptic segmentation benchmarks while also enabling flexible mask inpainting capabilities.
Plain English Explanation
The paper introduces a new technique for image understanding and manipulation that combines two important computer vision tasks: panoptic segmentation and mask inpainting.
Panoptic segmentation is the process of classifying every pixel in an image into either an "stuff" category (like sky, grass, or road) or an "thing" category (like a person, car, or animal), while also distinguishing individual object instances. This provides a comprehensive and detailed understanding of the contents of an image.
Mask inpainting involves filling in missing or damaged regions of an image in a realistic and semantically consistent way. This can be useful for tasks like object removal, image restoration, or content creation.
The key innovation of this paper is to use a single diffusion-based model to tackle both of these challenges simultaneously. Diffusion models are a type of generative AI that can learn to create new images by adding and then removing noise in a controlled way. By training this model on data with both segmentation and inpainting annotations, the authors are able to learn a shared representation that can perform both tasks effectively.
This joint approach has several benefits. It allows the model to leverage synergies between the two tasks, leading to better performance on each. It also enables flexible mask inpainting capabilities, where the model can fill in missing regions of an image while respecting the underlying semantic structure. Overall, this simple yet powerful technique represents an advance in the field of AI-powered image understanding and manipulation.
Technical Explanation
The proposed method, called "Latent Diffusion for Panoptic Segmentation and Mask Inpainting" (LDPMI), is built upon the success of diffusion models for image generation. Diffusion models work by gradually adding noise to an image and then learning to reverse this process to generate new images.
LDPMI extends this paradigm to the tasks of panoptic segmentation and mask inpainting. The model takes an input image and a set of binary masks indicating the regions to be inpainted. It then learns a shared latent representation that can be used to both predict the panoptic segmentation of the image and generate plausible content to fill in the masked regions.
The key innovation is the use of a single diffusion model to handle both tasks simultaneously. This is achieved by defining a joint training objective that combines segmentation and inpainting losses. During inference, the model can be used for either panoptic segmentation or mask inpainting by conditioning on the appropriate input.
Experiments on standard benchmarks show that LDPMI achieves competitive performance on panoptic segmentation while also enabling high-quality mask inpainting. The authors also demonstrate the flexibility of the approach, showing that it can handle a variety of inpainting scenarios, including partial object removal and large missing regions.
Critical Analysis
The paper presents a compelling and well-designed approach that successfully integrates panoptic segmentation and mask inpainting into a single diffusion-based framework. However, there are a few potential limitations and areas for further exploration:
-
Computational Complexity: Diffusion models can be computationally expensive to train and run, which may limit their real-world applicability, especially for resource-constrained devices. The authors do not provide a detailed analysis of the computational requirements of their approach.
-
Generalization to Diverse Datasets: The experiments in the paper focus on a few standard benchmarks, mainly in the natural image domain. It would be valuable to see how well the method generalizes to more diverse datasets, such as medical images or satellite imagery, where the underlying scene compositions and inpainting requirements may differ.
-
Interpretability and Explainability: As with many deep learning models, the internal workings of the diffusion-based approach may be opaque. Exploring ways to make the model's decision-making process more interpretable could enhance its trustworthiness and suitability for critical applications.
-
Potential Disruption and Semantic Digression: The authors do not discuss the potential risks or pitfalls of using a joint segmentation and inpainting model, such as the model introducing semantic distortions or hallucinating content that is inconsistent with the original scene.
Overall, the paper presents a novel and compelling approach that pushes the boundaries of what is possible with diffusion-based models. With further research and refinement to address the limitations mentioned above, this work could have a significant impact on the field of computer vision and image manipulation.
Conclusion
This paper introduces a simple yet effective latent diffusion approach for jointly tackling the tasks of panoptic segmentation and mask inpainting. By leveraging the power of diffusion models, the proposed method is able to learn a shared representation that can effectively perform both tasks, leading to competitive performance on segmentation benchmarks and flexible inpainting capabilities.
The key innovation of the work is the integration of these two important computer vision problems into a single framework, which allows the model to leverage synergies between the tasks and enables new applications, such as semantically-aware object removal and image restoration.
While the paper presents a promising approach, there are still opportunities for further research to address potential limitations around computational complexity, generalization to diverse datasets, and model interpretability. Overall, this work represents an exciting step forward in the quest to develop more powerful and versatile image understanding and manipulation tools powered by AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Simple Latent Diffusion Approach for Panoptic Segmentation and Mask Inpainting
Wouter Van Gansbeke, Bert De Brabandere
Panoptic and instance segmentation networks are often trained with specialized object detection modules, complex loss functions, and ad-hoc post-processing steps to manage the permutation-invariance of the instance masks. This work builds upon Stable Diffusion and proposes a latent diffusion approach for panoptic segmentation, resulting in a simple architecture that omits these complexities. Our training consists of two steps: (1) training a shallow autoencoder to project the segmentation masks to latent space; (2) training a diffusion model to allow image-conditioned sampling in latent space. This generative approach unlocks the exploration of mask completion or inpainting. The experimental validation on COCO and ADE20k yields strong segmentation results. Finally, we demonstrate our model's adaptability to multi-tasking by introducing learnable task embeddings.
Read more7/17/2024

0
Improving Text-guided Object Inpainting with Semantic Pre-inpainting
Yifu Chen, Jingwen Chen, Yingwei Pan, Yehao Li, Ting Yao, Zhineng Chen, Tao Mei
Recent years have witnessed the success of large text-to-image diffusion models and their remarkable potential to generate high-quality images. The further pursuit of enhancing the editability of images has sparked significant interest in the downstream task of inpainting a novel object described by a text prompt within a designated region in the image. Nevertheless, the problem is not trivial from two aspects: 1) Solely relying on one single U-Net to align text prompt and visual object across all the denoising timesteps is insufficient to generate desired objects; 2) The controllability of object generation is not guaranteed in the intricate sampling space of diffusion model. In this paper, we propose to decompose the typical single-stage object inpainting into two cascaded processes: 1) semantic pre-inpainting that infers the semantic features of desired objects in a multi-modal feature space; 2) high-fieldity object generation in diffusion latent space that pivots on such inpainted semantic features. To achieve this, we cascade a Transformer-based semantic inpainter and an object inpainting diffusion model, leading to a novel CAscaded Transformer-Diffusion (CAT-Diffusion) framework for text-guided object inpainting. Technically, the semantic inpainter is trained to predict the semantic features of the target object conditioning on unmasked context and text prompt. The outputs of the semantic inpainter then act as the informative visual prompts to guide high-fieldity object generation through a reference adapter layer, leading to controllable object inpainting. Extensive evaluations on OpenImages-V6 and MSCOCO validate the superiority of CAT-Diffusion against the state-of-the-art methods. Code is available at url{https://github.com/Nnn-s/CATdiffusion}.
Read more9/14/2024

0
Blended Latent Diffusion under Attention Control for Real-World Video Editing
Deyin Liu, Lin Yuanbo Wu, Xianghua Xie
Due to lack of fully publicly available text-to-video models, current video editing methods tend to build on pre-trained text-to-image generation models, however, they still face grand challenges in dealing with the local editing of video with temporal information. First, although existing methods attempt to focus on local area editing by a pre-defined mask, the preservation of the outside-area background is non-ideal due to the spatially entire generation of each frame. In addition, specially providing a mask by user is an additional costly undertaking, so an autonomous masking strategy integrated into the editing process is desirable. Last but not least, image-level pretrained model hasn't learned temporal information across frames of a video which is vital for expressing the motion and dynamics. In this paper, we propose to adapt a image-level blended latent diffusion model to perform local video editing tasks. Specifically, we leverage DDIM inversion to acquire the latents as background latents instead of the randomly noised ones to better preserve the background information of the input video. We further introduce an autonomous mask manufacture mechanism derived from cross-attention maps in diffusion steps. Finally, we enhance the temporal consistency across video frames by transforming the self-attention blocks of U-Net into temporal-spatial blocks. Through extensive experiments, our proposed approach demonstrates effectiveness in different real-world video editing tasks.
Read more9/6/2024
0
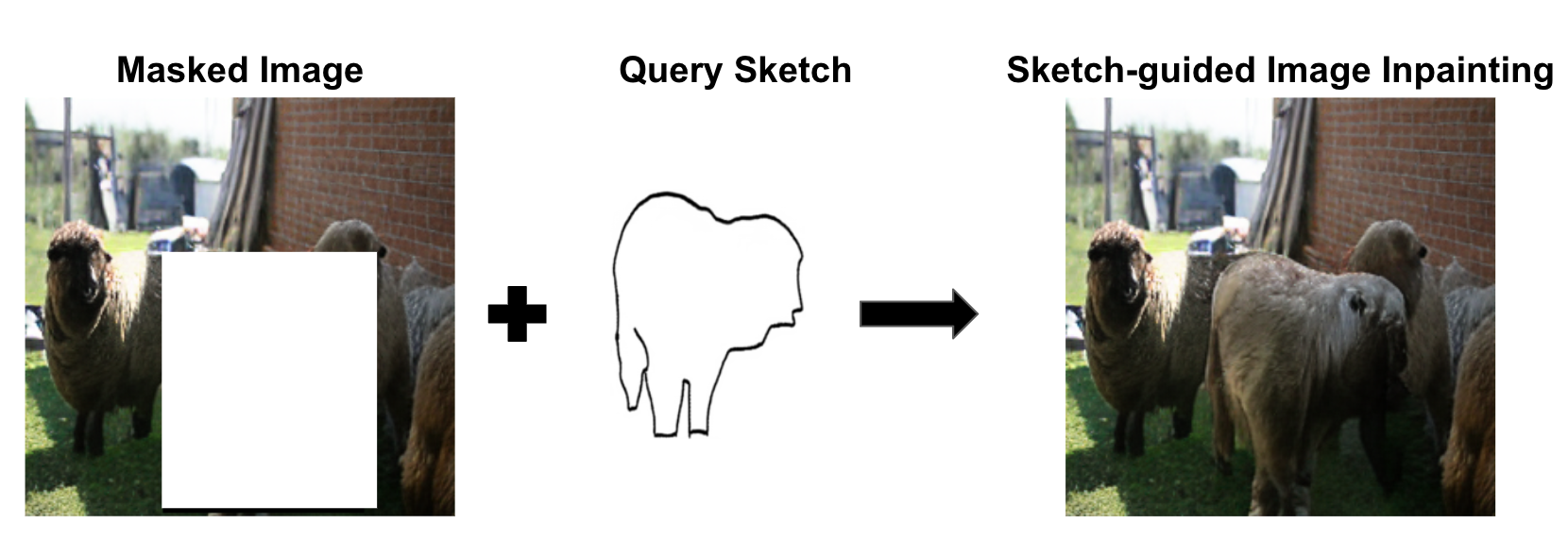
Sketch-guided Image Inpainting with Partial Discrete Diffusion Process
Nakul Sharma, Aditay Tripathi, Anirban Chakraborty, Anand Mishra
In this work, we study the task of sketch-guided image inpainting. Unlike the well-explored natural language-guided image inpainting, which excels in capturing semantic details, the relatively less-studied sketch-guided inpainting offers greater user control in specifying the object's shape and pose to be inpainted. As one of the early solutions to this task, we introduce a novel partial discrete diffusion process (PDDP). The forward pass of the PDDP corrupts the masked regions of the image and the backward pass reconstructs these masked regions conditioned on hand-drawn sketches using our proposed sketch-guided bi-directional transformer. The proposed novel transformer module accepts two inputs -- the image containing the masked region to be inpainted and the query sketch to model the reverse diffusion process. This strategy effectively addresses the domain gap between sketches and natural images, thereby, enhancing the quality of inpainting results. In the absence of a large-scale dataset specific to this task, we synthesize a dataset from the MS-COCO to train and extensively evaluate our proposed framework against various competent approaches in the literature. The qualitative and quantitative results and user studies establish that the proposed method inpaints realistic objects that fit the context in terms of the visual appearance of the provided sketch. To aid further research, we have made our code publicly available at https://github.com/vl2g/Sketch-Inpainting .
Read more4/19/2024