Tasks People Prompt: A Taxonomy of LLM Downstream Tasks in Software Verification and Falsification Approaches

0
🖼️
Sign in to get full access
Overview
- This paper investigates how software testing and verification research communities have been using large language models (LLMs) and prompting techniques.
- The researchers analyzed 80 papers to understand the blueprint of prompt-based solutions, including the types of downstream tasks and engineering patterns used.
- The goal is to validate whether downstream tasks are an adequate concept for conveying prompt-based solutions and to identify the number and nature of such tasks.
Plain English Explanation
Large language models (LLMs) have become a powerful tool for researchers and practitioners, who have been exploring ways to leverage their emergent capabilities. One approach is called "prompting," where users provide specific instructions or inputs to the LLM to generate desired outputs.
In this study, the researchers looked at 80 research papers to understand how the software testing and verification communities have been using prompting techniques with LLMs. They wanted to see if the idea of "downstream tasks" (specific objectives or problems the LLM is trained to solve) accurately captures the way prompting is being used in these fields.
The researchers also aimed to identify the different types of downstream tasks and engineering patterns that researchers have developed to tackle various software engineering problems, such as testing, debugging, vulnerability detection, and program verification.
Technical Explanation
The researchers conducted a systematic analysis of 80 research papers to investigate how the software testing and verification communities have been leveraging large language models (LLMs) and prompting techniques.
The key goals of the study were:
- To validate whether the concept of "downstream tasks" adequately captures the blueprint of prompt-based solutions.
- To identify the number and nature of such downstream tasks in the solutions.
To achieve these goals, the researchers developed a novel taxonomy of downstream tasks, which enabled them to identify engineering patterns across a wide range of software engineering problems, including testing, fuzzing, debugging, vulnerability detection, static analysis, and program verification.
The analysis revealed insights into how researchers and practitioners have been creatively using prompting to tackle various software engineering challenges. By systematically dissecting the papers, the researchers were able to uncover the different ways in which prompt-based solutions have been architected and deployed in these domains.
Critical Analysis
The researchers provide a comprehensive analysis of how the software testing and verification communities have been leveraging large language models and prompting techniques. The novel taxonomy of downstream tasks is a valuable contribution, as it allows for a structured understanding of the different ways prompting is being applied in these fields.
However, the paper does not delve deeply into the specific limitations or potential issues with the prompt-based solutions described. It would be helpful to have a more critical discussion of the potential biases, errors, or other challenges that may arise when using LLMs for these types of software engineering tasks.
Additionally, the paper focuses on research papers, but it would be interesting to see how the findings compare to the approaches and challenges faced by practitioners in real-world software development and deployment scenarios.
Conclusion
This study offers a detailed look at how the software testing and verification research communities have been harnessing the power of large language models and prompting techniques. By developing a novel taxonomy of downstream tasks, the researchers were able to uncover the diverse ways in which prompt-based solutions have been architected to tackle a range of software engineering problems.
The findings from this research have the potential to inform and inspire further advancements in the use of LLMs for software engineering tasks, as well as to highlight areas for future research and development. As the field continues to evolve, it will be important to maintain a critical eye on the limitations and challenges of these approaches to ensure they are implemented responsibly and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Tasks People Prompt: A Taxonomy of LLM Downstream Tasks in Software Verification and Falsification Approaches
V'ictor A. Braberman, Flavia Bonomo-Braberman, Yiannis Charalambous, Juan G. Colonna, Lucas C. Cordeiro, Rosiane de Freitas
Prompting has become one of the main approaches to leverage emergent capabilities of Large Language Models [Brown et al. NeurIPS 2020, Wei et al. TMLR 2022, Wei et al. NeurIPS 2022]. Recently, researchers and practitioners have been playing with prompts (e.g., In-Context Learning) to see how to make the most of pre-trained Language Models. By homogeneously dissecting more than a hundred articles, we investigate how software testing and verification research communities have leveraged LLMs capabilities. First, we validate that downstream tasks are adequate to convey a nontrivial modular blueprint of prompt-based proposals in scope. Moreover, we name and classify the concrete downstream tasks we recover in both validation research papers and solution proposals. In order to perform classification, mapping, and analysis, we also develop a novel downstream-task taxonomy. The main taxonomy requirement is to highlight commonalities while exhibiting variation points of task types that enable pinpointing emerging patterns in a varied spectrum of Software Engineering problems that encompasses testing, fuzzing, fault localization, vulnerability detection, static analysis, and program verification approaches. Avenues for future research are also discussed based on conceptual clusters induced by the taxonomy.
Read more9/10/2024
🌀
0
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
Sylvain Kouemo Ngassom, Arghavan Moradi Dakhel, Florian Tambon, Foutse Khomh
LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
Read more5/24/2024
0
Prompt Design Matters for Computational Social Science Tasks but in Unpredictable Ways
Shubham Atreja, Joshua Ashkinaze, Lingyao Li, Julia Mendelsohn, Libby Hemphill
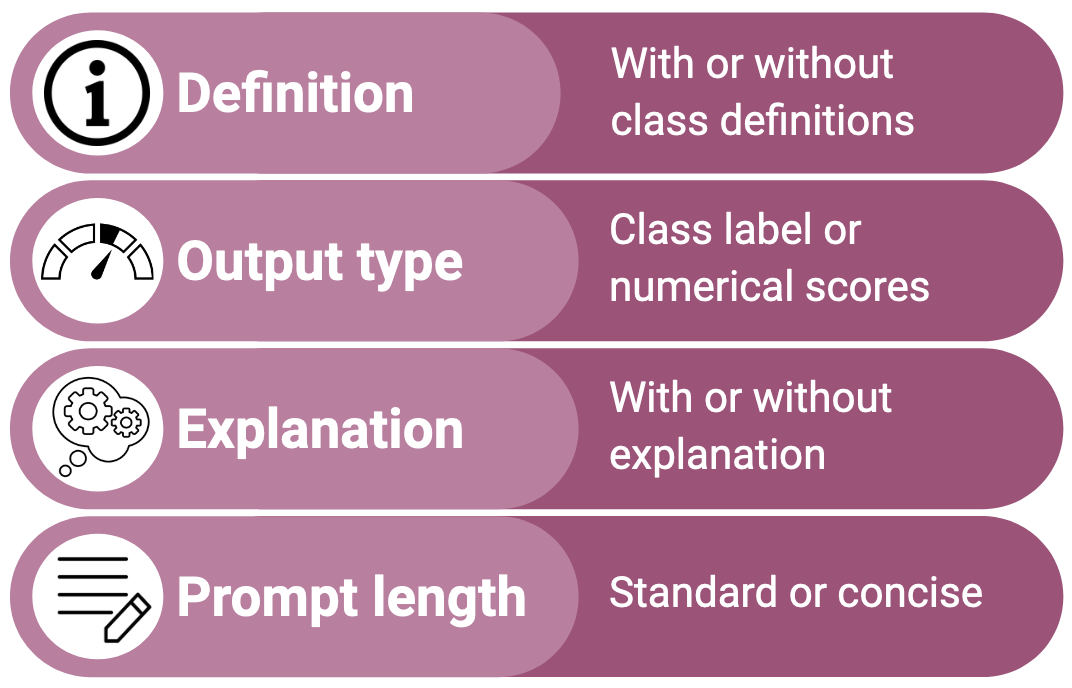
Manually annotating data for computational social science tasks can be costly, time-consuming, and emotionally draining. While recent work suggests that LLMs can perform such annotation tasks in zero-shot settings, little is known about how prompt design impacts LLMs' compliance and accuracy. We conduct a large-scale multi-prompt experiment to test how model selection (ChatGPT, PaLM2, and Falcon7b) and prompt design features (definition inclusion, output type, explanation, and prompt length) impact the compliance and accuracy of LLM-generated annotations on four CSS tasks (toxicity, sentiment, rumor stance, and news frames). Our results show that LLM compliance and accuracy are highly prompt-dependent. For instance, prompting for numerical scores instead of labels reduces all LLMs' compliance and accuracy. The overall best prompting setup is task-dependent, and minor prompt changes can cause large changes in the distribution of generated labels. By showing that prompt design significantly impacts the quality and distribution of LLM-generated annotations, this work serves as both a warning and practical guide for researchers and practitioners.
Read more6/19/2024
0
Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models
Devichand Budagam, Sankalp KJ, Ashutosh Kumar, Vinija Jain, Aman Chadha
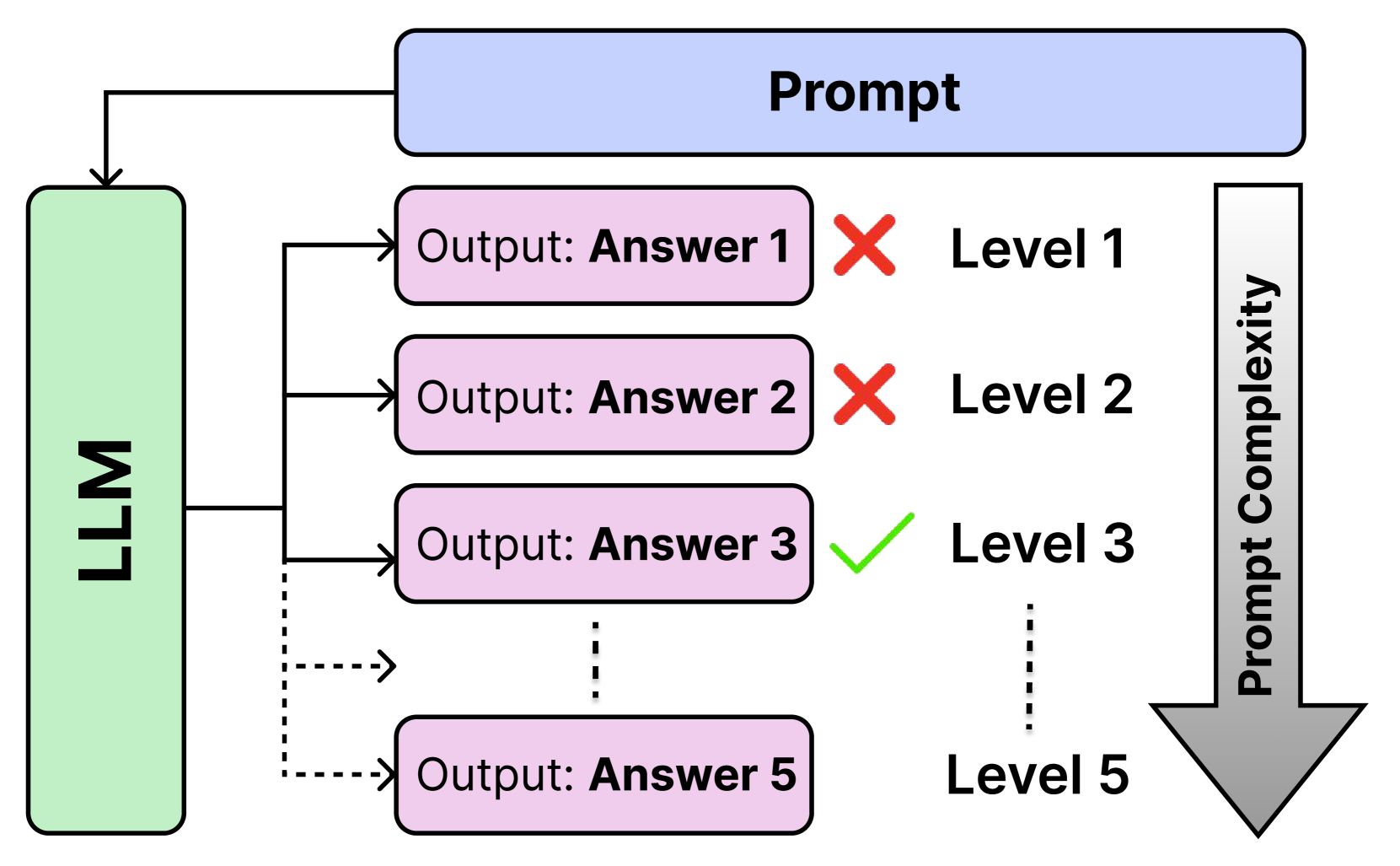
Assessing the effectiveness of large language models (LLMs) in addressing diverse tasks is essential for comprehending their strengths and weaknesses. Conventional evaluation techniques typically apply a single prompting strategy uniformly across datasets, not considering the varying degrees of task complexity. We introduce the Hierarchical Prompting Taxonomy (HPT), a taxonomy that employs a Hierarchical Prompt Framework (HPF) composed of five unique prompting strategies, arranged from the simplest to the most complex, to assess LLMs more precisely and to offer a clearer perspective. This taxonomy assigns a score, called the Hierarchical Prompting Score (HP-Score), to datasets as well as LLMs based on the rules of the taxonomy, providing a nuanced understanding of their ability to solve diverse tasks and offering a universal measure of task complexity. Additionally, we introduce the Adaptive Hierarchical Prompt framework, which automates the selection of appropriate prompting strategies for each task. This study compares manual and adaptive hierarchical prompt frameworks using four instruction-tuned LLMs, namely Llama 3 8B, Phi 3 3.8B, Mistral 7B, and Gemma 7B, across four datasets: BoolQ, CommonSenseQA (CSQA), IWSLT-2017 en-fr (IWSLT), and SamSum. Experiments demonstrate the effectiveness of HPT, providing a reliable way to compare different tasks and LLM capabilities. This paper leads to the development of a universal evaluation metric that can be used to evaluate both the complexity of the datasets and the capabilities of LLMs. The implementation of both manual HPF and adaptive HPF is publicly available.
Read more6/28/2024