UDA: A Benchmark Suite for Retrieval Augmented Generation in Real-world Document Analysis

0

Sign in to get full access
Overview
- The paper introduces UDA, a benchmark suite for evaluating retrieval-augmented generation models in real-world document analysis tasks.
- Retrieval-augmented generation combines language models with information retrieval to generate output that is grounded in relevant source documents.
- UDA includes a diverse set of real-world tasks such as question answering, summarization, and fact-checking, with datasets covering a range of domains.
Plain English Explanation
The researchers have developed a new benchmark called UDA to test how well AI systems can combine language models with information retrieval to solve real-world document analysis tasks. These tasks involve generating output (like answers to questions or summaries of documents) by drawing on relevant source materials.
The UDA benchmark includes a variety of challenging tasks covering areas like question answering, summarization, and fact-checking. The datasets span many different domains, reflecting the diverse range of real-world scenarios these systems need to handle. By providing this comprehensive benchmark, the researchers aim to drive progress in retrieval-augmented generation - an approach that combines the strengths of language models and information retrieval to produce more grounded and informative outputs.
Technical Explanation
The paper introduces the UDA benchmark suite for evaluating retrieval-augmented generation models on real-world document analysis tasks. Retrieval-augmented generation combines large language models with information retrieval to generate outputs that are grounded in relevant source documents.
The UDA benchmark includes 7 diverse tasks spanning question answering, summarization, and fact-checking, with datasets covering domains such as news, Wikipedia, and scientific literature. The tasks are designed to test a model's ability to effectively retrieve and integrate relevant information from source documents to produce high-quality responses.
The paper provides detailed descriptions of the tasks, datasets, and evaluation metrics in UDA. It also reports baseline results using a retrieval-augmented generation model, highlighting the challenges posed by the benchmark. The authors argue that UDA can serve as a comprehensive testbed to drive progress in this important research area.
Critical Analysis
The authors make a compelling case for the need to develop more capable retrieval-augmented generation models that can handle real-world document analysis tasks. The UDA benchmark represents an important step forward, providing a diverse and challenging set of tasks to evaluate the current state-of-the-art.
One potential limitation is the reliance on manually curated datasets, which may not fully capture the breadth of real-world variation. Additionally, the benchmark does not address issues around the dynamic relevance of documents or collaborative retrieval-augmented generation, which may be important for some applications.
Further research is needed to develop more robust and generalizable retrieval-augmented generation models that can overcome the challenges posed by the UDA benchmark. Exploring techniques like dynamic document relevance and collaborative approaches may be promising avenues for future work.
Conclusion
The UDA benchmark represents an important contribution to the field of retrieval-augmented generation, providing a comprehensive testbed for evaluating the capabilities of AI systems on real-world document analysis tasks. By combining language models with information retrieval, these systems have the potential to produce more grounded and informative outputs, with applications across a wide range of domains. The UDA benchmark sets a new standard for evaluating progress in this area and is likely to drive further advancements in this crucial research area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UDA: A Benchmark Suite for Retrieval Augmented Generation in Real-world Document Analysis
Yulong Hui, Yao Lu, Huanchen Zhang
The use of Retrieval-Augmented Generation (RAG) has improved Large Language Models (LLMs) in collaborating with external data, yet significant challenges exist in real-world scenarios. In areas such as academic literature and finance question answering, data are often found in raw text and tables in HTML or PDF formats, which can be lengthy and highly unstructured. In this paper, we introduce a benchmark suite, namely Unstructured Document Analysis (UDA), that involves 2,965 real-world documents and 29,590 expert-annotated Q&A pairs. We revisit popular LLM- and RAG-based solutions for document analysis and evaluate the design choices and answer qualities across multiple document domains and diverse query types. Our evaluation yields interesting findings and highlights the importance of data parsing and retrieval. We hope our benchmark can shed light and better serve real-world document analysis applications. The benchmark suite and code can be found at https://github.com/qinchuanhui/UDA-Benchmark.
Read more6/24/2024

0
Customized Retrieval Augmented Generation and Benchmarking for EDA Tool Documentation QA
Yuan Pu, Zhuolun He, Tairu Qiu, Haoyuan Wu, Bei Yu
Retrieval augmented generation (RAG) enhances the accuracy and reliability of generative AI models by sourcing factual information from external databases, which is extensively employed in document-grounded question-answering (QA) tasks. Off-the-shelf RAG flows are well pretrained on general-purpose documents, yet they encounter significant challenges when being applied to knowledge-intensive vertical domains, such as electronic design automation (EDA). This paper addresses such issue by proposing a customized RAG framework along with three domain-specific techniques for EDA tool documentation QA, including a contrastive learning scheme for text embedding model fine-tuning, a reranker distilled from proprietary LLM, and a generative LLM fine-tuned with high-quality domain corpus. Furthermore, we have developed and released a documentation QA evaluation benchmark, ORD-QA, for OpenROAD, an advanced RTL-to-GDSII design platform. Experimental results demonstrate that our proposed RAG flow and techniques have achieved superior performance on ORD-QA as well as on a commercial tool, compared with state-of-the-arts. The ORD-QA benchmark and the training dataset for our customized RAG flow are open-source at https://github.com/lesliepy99/RAG-EDA.
Read more7/29/2024
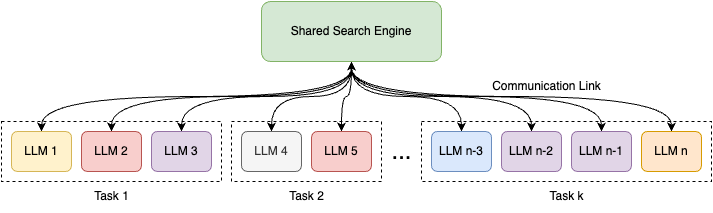
0
Towards a Search Engine for Machines: Unified Ranking for Multiple Retrieval-Augmented Large Language Models
Alireza Salemi, Hamed Zamani
This paper introduces uRAG--a framework with a unified retrieval engine that serves multiple downstream retrieval-augmented generation (RAG) systems. Each RAG system consumes the retrieval results for a unique purpose, such as open-domain question answering, fact verification, entity linking, and relation extraction. We introduce a generic training guideline that standardizes the communication between the search engine and the downstream RAG systems that engage in optimizing the retrieval model. This lays the groundwork for us to build a large-scale experimentation ecosystem consisting of 18 RAG systems that engage in training and 18 unknown RAG systems that use the uRAG as the new users of the search engine. Using this experimentation ecosystem, we answer a number of fundamental research questions that improve our understanding of promises and challenges in developing search engines for machines.
Read more5/2/2024

0
RAGBench: Explainable Benchmark for Retrieval-Augmented Generation Systems
Robert Friel, Masha Belyi, Atindriyo Sanyal
Retrieval-Augmented Generation (RAG) has become a standard architectural pattern for incorporating domain-specific knowledge into user-facing chat applications powered by Large Language Models (LLMs). RAG systems are characterized by (1) a document retriever that queries a domain-specific corpus for context information relevant to an input query, and (2) an LLM that generates a response based on the provided query and context. However, comprehensive evaluation of RAG systems remains a challenge due to the lack of unified evaluation criteria and annotated datasets. In response, we introduce RAGBench: the first comprehensive, large-scale RAG benchmark dataset of 100k examples. It covers five unique industry-specific domains and various RAG task types. RAGBench examples are sourced from industry corpora such as user manuals, making it particularly relevant for industry applications. Further, we formalize the TRACe evaluation framework: a set of explainable and actionable RAG evaluation metrics applicable across all RAG domains. We release the labeled dataset at https://huggingface.co/datasets/rungalileo/ragbench. RAGBench explainable labels facilitate holistic evaluation of RAG systems, enabling actionable feedback for continuous improvement of production applications. Thorough extensive benchmarking, we find that LLM-based RAG evaluation methods struggle to compete with a finetuned RoBERTa model on the RAG evaluation task. We identify areas where existing approaches fall short and propose the adoption of RAGBench with TRACe towards advancing the state of RAG evaluation systems.
Read more7/17/2024