Vision Language Models for Spreadsheet Understanding: Challenges and Opportunities

0

Sign in to get full access
Overview
This research paper explores the challenges and opportunities in using vision-language models for understanding spreadsheet data. It examines the unique characteristics of spreadsheets and how they differ from traditional visual and textual inputs, posing new challenges for AI systems. The paper also highlights the potential benefits of applying advanced vision-language models to spreadsheet analysis, such as automating data extraction, understanding formulas, and generating summaries.
Plain English Explanation
Spreadsheets are an essential tool for managing and analyzing data, but they can be complex and difficult for computers to understand. Traditional AI systems struggle with the unique structure and content of spreadsheets, which combine visual elements like tables and charts with textual information like formulas and annotations.
This research paper investigates how recent advancements in vision-language modeling could be leveraged to improve spreadsheet understanding. Vision-language models are AI systems that can process and integrate both visual and textual information, allowing them to potentially understand the complex interplay between the different components of a spreadsheet.
The paper explores the unique challenges posed by spreadsheets, such as interpreting the meaning of cell contents, recognizing the structure and layout of the data, and understanding the logic encoded in formulas. It also highlights the potential benefits of using vision-language models for spreadsheet analysis, including automating data extraction, generating summaries, and even suggesting improvements to spreadsheet design.
Technical Explanation
The paper first reviews the relevant literature on vision-language models and their potential applications in domains like document understanding and task automation. It then delves into the unique characteristics of spreadsheets that pose challenges for these models, such as the mixture of structured and unstructured data, the importance of logical reasoning for interpreting formulas, and the need to understand the spatial layout and visual cues.
The paper proposes several key research directions for applying vision-language models to spreadsheet understanding, including developing specialized architectures that can effectively process the combination of visual and textual information, leveraging pre-training on large-scale datasets to capture the nuances of spreadsheet data, and designing evaluation benchmarks that capture the full complexity of spreadsheet analysis tasks.
The authors also discuss the potential benefits of vision-language models in spreadsheet understanding, such as automating data extraction, formula interpretation, and the generation of summaries and insights. They highlight how these capabilities could significantly improve the efficiency and productivity of spreadsheet-based workflows.
Critical Analysis
The paper provides a comprehensive overview of the challenges and opportunities in applying vision-language models to spreadsheet understanding, but it also acknowledges several limitations and areas for further research. For example, the authors note that the unique characteristics of spreadsheets may require specialized architectural designs or pre-training approaches that go beyond the standard vision-language model formulations.
Additionally, the paper highlights the need for robust evaluation benchmarks that capture the full complexity of spreadsheet analysis tasks, which can be challenging to develop and standardize. The authors also caution that the interpretability and trustworthiness of vision-language models in the context of spreadsheet understanding will be a critical concern, as users will need to understand and validate the reasoning behind the models' outputs.
Further research could explore ways to make vision-language models more transparent and explainable, potentially through the use of attention mechanisms or other interpretability techniques. Investigating the robustness of these models to common spreadsheet errors and anomalies would also be a valuable area of study.
Conclusion
This research paper highlights the significant potential of vision-language models for advancing spreadsheet understanding, but also acknowledges the unique challenges posed by the complex and multifaceted nature of spreadsheet data. By addressing these challenges, the development of more capable and trustworthy vision-language models could lead to substantial improvements in spreadsheet-based workflows, enabling more efficient data analysis, formula interpretation, and decision-making. As the field of AI continues to progress, this research represents an important step towards bridging the gap between human and machine understanding of the ubiquitous spreadsheet.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Vision Language Models for Spreadsheet Understanding: Challenges and Opportunities
Shiyu Xia, Junyu Xiong, Haoyu Dong, Jianbo Zhao, Yuzhang Tian, Mengyu Zhou, Yeye He, Shi Han, Dongmei Zhang
This paper explores capabilities of Vision Language Models on spreadsheet comprehension. We propose three self-supervised challenges with corresponding evaluation metrics to comprehensively evaluate VLMs on Optical Character Recognition (OCR), spatial perception, and visual format recognition. Additionally, we utilize the spreadsheet table detection task to assess the overall performance of VLMs by integrating these challenges. To probe VLMs more finely, we propose three spreadsheet-to-image settings: column width adjustment, style change, and address augmentation. We propose variants of prompts to address the above tasks in different settings. Notably, to leverage the strengths of VLMs in understanding text rather than two-dimensional positioning, we propose to decode cell values on the four boundaries of the table in spreadsheet boundary detection. Our findings reveal that VLMs demonstrate promising OCR capabilities but produce unsatisfactory results due to cell omission and misalignment, and they notably exhibit insufficient spatial and format recognition skills, motivating future work to enhance VLMs' spreadsheet data comprehension capabilities using our methods to generate extensive spreadsheet-image pairs in various settings.
Read more8/12/2024
0
Response Wide Shut: Surprising Observations in Basic Vision Language Model Capabilities
Shivam Chandhok, Wan-Cyuan Fan, Leonid Sigal
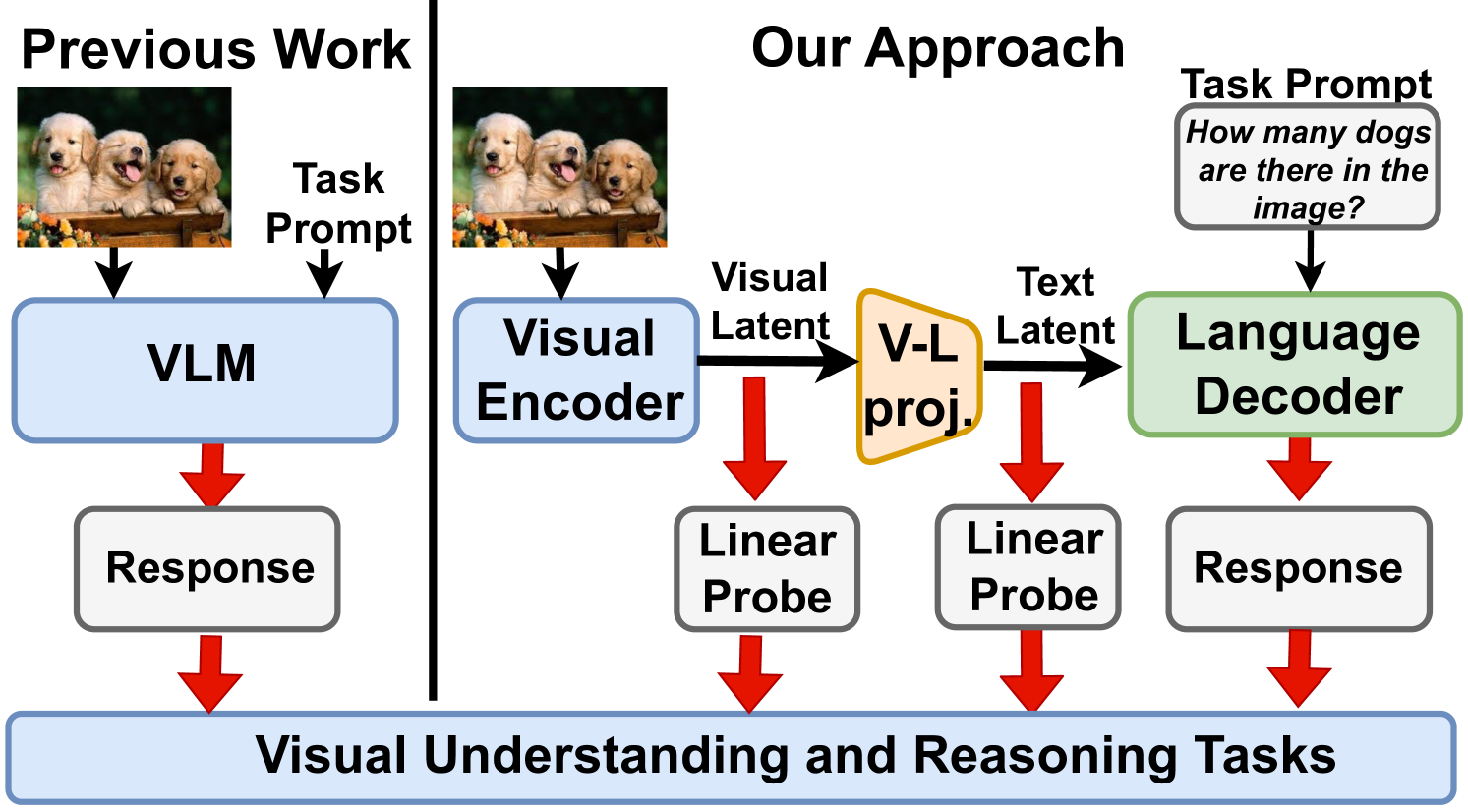
Vision-Language Models (VLMs) have emerged as general purpose tools for addressing a variety of complex computer vision problems. Such models have been shown to be highly capable, but, at the same time, also lacking some basic visual understanding skills. In this paper, we set out to understand the limitations of SoTA VLMs on fundamental visual tasks: object classification, understanding spatial arrangement, and ability to delineate individual object instances (through counting), by constructing a series of tests that probe which components of design, specifically, maybe lacking. Importantly, we go significantly beyond the current benchmarks, that simply measure final performance of VLM, by also comparing and contrasting it to performance of probes trained directly on features obtained from visual encoder (image embeddings), as well as intermediate vision-language projection used to bridge image-encoder and LLM-decoder ouput in many SoTA models (e.g., LLaVA, BLIP, InstructBLIP). In doing so, we uncover nascent shortcomings in VLMs response and make a number of important observations which could help train and develop more effective VLM models in future.
Read more8/14/2024

0
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
Read more6/24/2024

1
An Introduction to Vision-Language Modeling
Florian Bordes, Richard Yuanzhe Pang, Anurag Ajay, Alexander C. Li, Adrien Bardes, Suzanne Petryk, Oscar Ma~nas, Zhiqiu Lin, Anas Mahmoud, Bargav Jayaraman, Mark Ibrahim, Melissa Hall, Yunyang Xiong, Jonathan Lebensold, Candace Ross, Srihari Jayakumar, Chuan Guo, Diane Bouchacourt, Haider Al-Tahan, Karthik Padthe, Vasu Sharma, Hu Xu, Xiaoqing Ellen Tan, Megan Richards, Samuel Lavoie, Pietro Astolfi, Reyhane Askari Hemmat, Jun Chen, Kushal Tirumala, Rim Assouel, Mazda Moayeri, Arjang Talattof, Kamalika Chaudhuri, Zechun Liu, Xilun Chen, Quentin Garrido, Karen Ullrich, Aishwarya Agrawal, Kate Saenko, Asli Celikyilmaz, Vikas Chandra
Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Read more5/28/2024