We're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation

0
Sign in to get full access
Overview
- This paper explores how language models can be adapted to handle different types of linguistic variation, such as dialects and accents.
- The authors investigate the performance of language models on various tasks involving linguistic diversity, including text generation, translation, and sentiment analysis.
- They propose several techniques for improving language model adaptation, including data augmentation, fine-tuning, and prompt engineering.
Plain English Explanation
The paper looks at how large language models can be adjusted to work well with different forms of language, such as regional dialects or accents. Language models are AI systems that can generate human-like text, translate between languages, and analyze the sentiment of text.
The researchers tested how well these models performed on tasks involving diverse language, like evaluating their reasoning abilities or using contrast sets to test their capabilities. They found that language models often struggle with linguistic variation.
To help language models work better with diverse language, the researchers tried several techniques, such as:
- Expanding the training data with more examples of different dialects and accents
- Fine-tuning the models on specific types of linguistic variation
- Carefully designing the prompts used to interact with the models
The goal is to make language models that can assist researchers and be useful in real-world applications involving diverse populations and communication styles.
Technical Explanation
The paper examines the ability of large language models to adapt to different types of linguistic variation, including dialects, accents, and other forms of language diversity. The authors conduct a series of experiments to evaluate the performance of state-of-the-art language models on various NLP tasks involving linguistically diverse data.
The experiments cover a range of applications, such as text generation, translation, and sentiment analysis. The researchers use a combination of standard evaluation metrics and custom-designed contrast sets to assess the models' strengths and weaknesses in handling linguistic variation.
To improve language model adaptation, the authors explore several techniques, including data augmentation, fine-tuning, and prompt engineering. Data augmentation involves expanding the training data with more examples of diverse linguistic phenomena. Fine-tuning refers to further training the models on specific types of linguistic variation. Prompt engineering focuses on designing the input prompts used to interact with the language models in a way that encourages them to handle linguistic diversity more effectively.
The results show that while language models can exhibit some degree of robustness to linguistic variation, they still struggle in many cases. The authors identify several areas for improvement, such as better modeling of sociolinguistic features and developing more targeted adaptation strategies.
Critical Analysis
The paper provides a valuable contribution to the field of natural language processing by highlighting the challenges that large language models face when dealing with linguistic diversity. The authors have designed a comprehensive set of experiments to systematically evaluate model performance across a range of tasks and linguistic phenomena.
One potential limitation of the study is the reliance on relatively small datasets for some of the experiments, which could limit the generalizability of the findings. Additionally, the paper does not delve deeply into the underlying reasons why language models struggle with linguistic variation, which could help inform more targeted solutions.
Furthermore, the authors do not discuss the potential societal implications of language models' inability to handle linguistic diversity, such as the risk of perpetuating biases or excluding certain populations. Exploring these issues could be an important area for future research.
Despite these minor caveats, the paper makes a strong case for the need to prioritize linguistic diversity in the development and evaluation of language models. The proposed techniques for improving adaptation, such as data augmentation and prompt engineering, provide a promising starting point for further research and development in this area.
Conclusion
This paper highlights the critical need for language models to be able to handle diverse forms of language, including dialects, accents, and other linguistic variation. The authors' comprehensive evaluation of model performance on a range of tasks reveals significant challenges that current language models face in this regard.
By exploring techniques like data augmentation, fine-tuning, and prompt engineering, the researchers demonstrate potential pathways for improving language model adaptation. Addressing linguistic diversity is crucial for ensuring that language AI systems are inclusive, accessible, and beneficial to all members of society.
As the field of natural language processing continues to advance, it will be essential for researchers and developers to prioritize the development of language models that can assist researchers and serve diverse populations effectively, regardless of their linguistic background or communication style.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
We're Calling an Intervention: Taking a Closer Look at Language Model Adaptation to Different Types of Linguistic Variation
Aarohi Srivastava, David Chiang
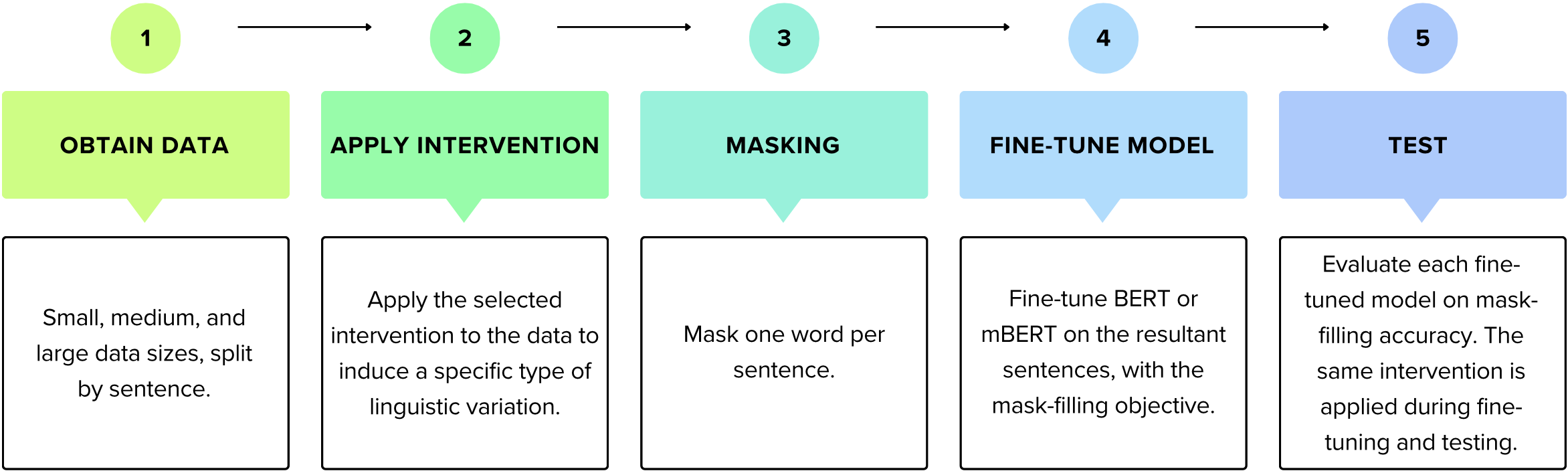
We present a suite of experiments that allow us to understand the underlying challenges of language model adaptation to nonstandard text. We do so by designing interventions that approximate several types of linguistic variation and their interactions with existing biases of language models. Applying our interventions during language model adaptation with varying size and nature of training data, we gain important insights into when knowledge transfer can be successful, as well as the aspects of linguistic variation that are particularly difficult for language models to deal with. For instance, on text with character-level variation, performance improves with even a few training examples but approaches a plateau, suggesting that more data is not the solution. In contrast, on text with variation involving new words or meanings, far more data is needed, but it leads to a massive breakthrough in performance. Our findings reveal that existing models lack the necessary infrastructure to handle diverse forms of nonstandard text and linguistic variation, guiding the development of more resilient language modeling techniques for the future. We make the code for our interventions, which can be applied to any English text data, publicly available.
Read more6/18/2024
👨🏫
0
Data-Augmentation-Based Dialectal Adaptation for LLMs
Fahim Faisal, Antonios Anastasopoulos
This report presents GMUNLP's participation to the Dialect-Copa shared task at VarDial 2024, which focuses on evaluating the commonsense reasoning capabilities of large language models (LLMs) on South Slavic micro-dialects. The task aims to assess how well LLMs can handle non-standard dialectal varieties, as their performance on standard languages is already well-established. We propose an approach that combines the strengths of different types of language models and leverages data augmentation techniques to improve task performance on three South Slavic dialects: Chakavian, Cherkano, and Torlak. We conduct experiments using a language-family-focused encoder-based model (BERTi'c) and a domain-agnostic multilingual model (AYA-101). Our results demonstrate that the proposed data augmentation techniques lead to substantial performance gains across all three test datasets in the open-source model category. This work highlights the practical utility of data augmentation and the potential of LLMs in handling non-standard dialectal varieties, contributing to the broader goal of advancing natural language understanding in low-resource and dialectal settings. Code:https://github.com/ffaisal93/dialect_copa
Read more4/15/2024
💬
0
Targeted Multilingual Adaptation for Low-resource Language Families
C. M. Downey, Terra Blevins, Dhwani Serai, Dwija Parikh, Shane Steinert-Threlkeld
The massively-multilingual training of multilingual models is known to limit their utility in any one language, and they perform particularly poorly on low-resource languages. However, there is evidence that low-resource languages can benefit from targeted multilinguality, where the model is trained on closely related languages. To test this approach more rigorously, we systematically study best practices for adapting a pre-trained model to a language family. Focusing on the Uralic family as a test case, we adapt XLM-R under various configurations to model 15 languages; we then evaluate the performance of each experimental setting on two downstream tasks and 11 evaluation languages. Our adapted models significantly outperform mono- and multilingual baselines. Furthermore, a regression analysis of hyperparameter effects reveals that adapted vocabulary size is relatively unimportant for low-resource languages, and that low-resource languages can be aggressively up-sampled during training at little detriment to performance in high-resource languages. These results introduce new best practices for performing language adaptation in a targeted setting.
Read more5/22/2024
➖
0
Modeling Orthographic Variation in Occitan's Dialects
Zachary William Hopton (Language,Space Lab, University of Zurich), Noemi Aepli (Department of Computational Linguistics, University of Zurich)
Effectively normalizing textual data poses a considerable challenge, especially for low-resource languages lacking standardized writing systems. In this study, we fine-tuned a multilingual model with data from several Occitan dialects and conducted a series of experiments to assess the model's representations of these dialects. For evaluation purposes, we compiled a parallel lexicon encompassing four Occitan dialects. Intrinsic evaluations of the model's embeddings revealed that surface similarity between the dialects strengthened representations. When the model was further fine-tuned for part-of-speech tagging and Universal Dependency parsing, its performance was robust to dialectical variation, even when trained solely on part-of-speech data from a single dialect. Our findings suggest that large multilingual models minimize the need for spelling normalization during pre-processing.
Read more5/1/2024