Lucky 52: How Many Languages Are Needed to Instruction Fine-Tune Large Language Models?
2404.04850
0
0
Abstract
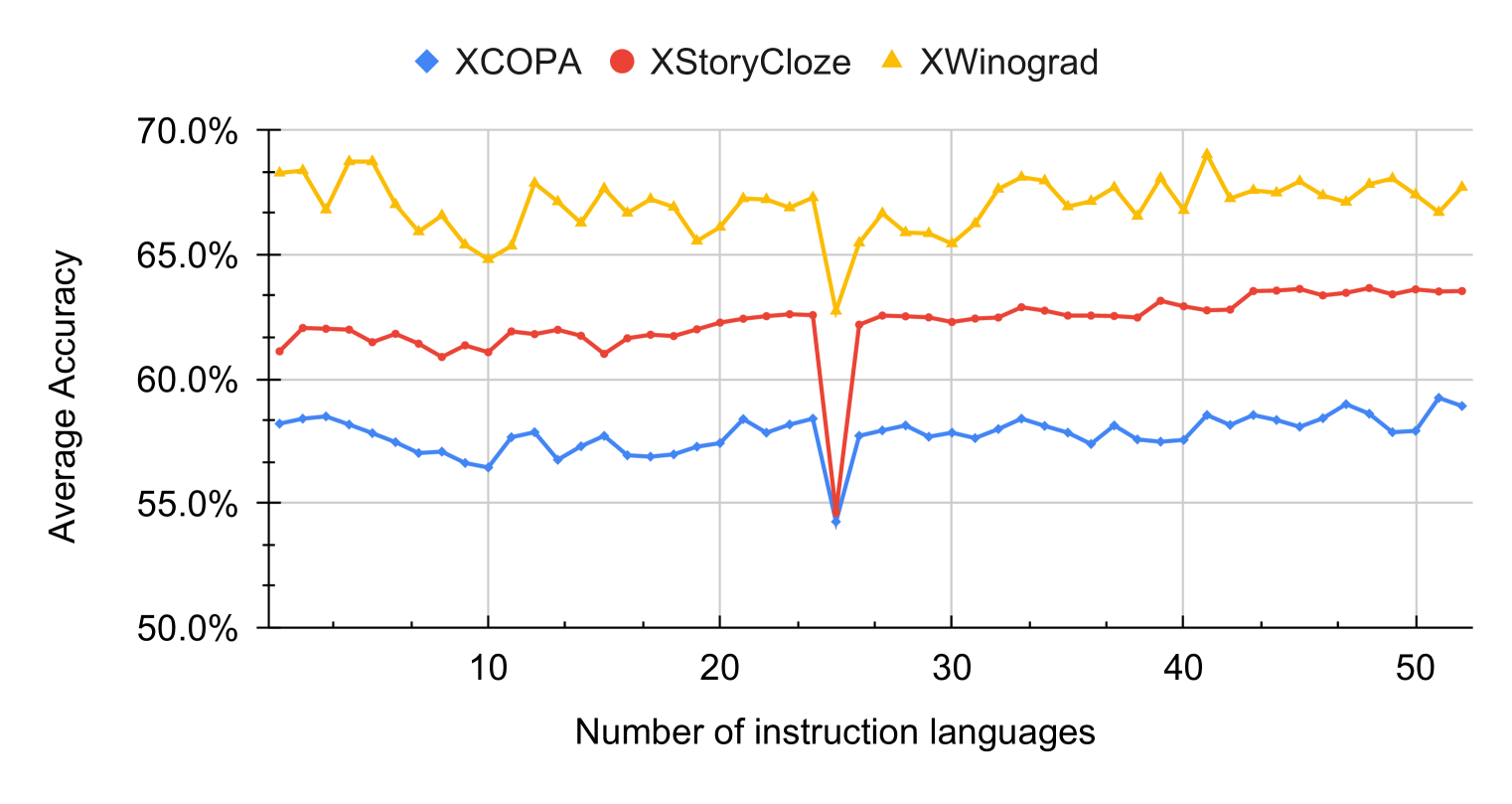
Fine-tuning large language models for multilingual downstream tasks requires a diverse set of languages to capture the nuances and structures of different linguistic contexts effectively. While the specific number varies depending on the desired scope and target languages, we argue that the number of languages, language exposure, and similarity that incorporate the selection of languages for fine-tuning are some important aspects to examine. By fine-tuning large multilingual models on 1 to 52 languages, this paper answers one question: How many languages are needed in instruction fine-tuning for multilingual tasks? We investigate how multilingual instruction fine-tuned models behave on multilingual benchmarks with an increasing number of languages and discuss our findings from the perspective of language exposure and similarity.
Create account to get full access
Overview
- Explores how many languages are needed to effectively fine-tune large language models using instruction-based training
- Investigates the impact of increasing the number of languages on the performance of multilingual language models
- Provides insights into the relationship between the number of training languages and the quality of cross-lingual transfer
Plain English Explanation
This research paper examines a technique called "instruction fine-tuning" to improve the performance of large language models that can understand and generate text in multiple languages. The key idea is to train these models not just on general text, but on specific instructions or tasks, which can help them become more capable at understanding and completing a wide variety of language-based activities.
The researchers tested how the number of languages used in this instruction fine-tuning process affects the models' performance. They found that as the number of training languages increased, the models generally became better at understanding and completing tasks in languages they hadn't seen during training. This suggests that using a wider range of languages during the fine-tuning process can lead to more versatile and capable multilingual language models.
The paper provides valuable insights into the tradeoffs involved in developing high-performing multilingual language models. By understanding how the number of training languages impacts model performance, researchers and developers can make more informed decisions about how to structure their training data and approaches to get the best results.
Technical Explanation
The paper explores multilingual pretraining and instruction tuning to improve cross-lingual performance of large language models. It investigates the impact of increasing the number of training languages on the quality of cross-lingual transfer.
The key idea is to fine-tune large language models using instruction-based training, where the models are tasked with completing specific language-based activities or "instructions" during the fine-tuning process. The researchers test how the number of languages used in this instruction fine-tuning affects the models' performance on cross-lingual tasks.
Their experiments show that as the number of training languages increases, the models generally become better at understanding and completing tasks in languages they haven't seen before. This suggests that using a wider range of languages during the fine-tuning process can lead to more versatile and capable multilingual language models.
The paper's findings have implications for the development of large language models for spoken language understanding and other cross-lingual applications. By understanding the relationship between the number of training languages and model performance, researchers can make more informed decisions about how to structure their training data and approaches.
Critical Analysis
The paper provides a thorough and well-designed study on the impact of multilingual instruction fine-tuning on the cross-lingual capabilities of large language models. The researchers acknowledge some potential limitations, such as the need to test their approach on a wider range of language pairs and tasks to fully understand its generalizability.
Additionally, the paper does not explore the psychometric and predictive power of large language models in depth, which could be an important consideration for certain applications. Further research may be needed to understand how the number of training languages affects these higher-level capabilities.
The paper also does not delve into efficient approaches for studying cross-lingual transfer in multilingual models, which could be a valuable area for future work. Developing more streamlined methodologies for evaluating cross-lingual performance could enable faster iterations and advancements in this field.
Overall, the paper presents a strong and thoughtful analysis that contributes valuable insights to the ongoing research on improving the cross-lingual capabilities of large language models. Further exploration of the topics and limitations discussed could lead to even more impactful developments in this important area of natural language processing.
Conclusion
This research paper provides a comprehensive investigation into the relationship between the number of training languages and the cross-lingual performance of large language models using instruction fine-tuning. The key finding is that increasing the number of training languages generally improves the models' ability to understand and complete tasks in languages they haven't seen before.
These insights have important implications for the development of versatile and capable multilingual language models that can be applied to a wide range of cross-lingual applications, from spoken language understanding to psychometric and predictive modeling. By carefully considering the tradeoffs involved in multilingual training, researchers and practitioners can build more effective and efficient models that can better serve the needs of diverse language communities around the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Multilingual Instruction Tuning With Just a Pinch of Multilinguality
Uri Shaham, Jonathan Herzig, Roee Aharoni, Idan Szpektor, Reut Tsarfaty, Matan Eyal
0
0
As instruction-tuned large language models (LLMs) gain global adoption, their ability to follow instructions in multiple languages becomes increasingly crucial. In this work, we investigate how multilinguality during instruction tuning of a multilingual LLM affects instruction-following across languages from the pre-training corpus. We first show that many languages transfer some instruction-following capabilities to other languages from even monolingual tuning. Furthermore, we find that only 40 multilingual examples integrated in an English tuning set substantially improve multilingual instruction-following, both in seen and unseen languages during tuning. In general, we observe that models tuned on multilingual mixtures exhibit comparable or superior performance in multiple languages compared to monolingually tuned models, despite training on 10x fewer examples in those languages. Finally, we find that diversifying the instruction tuning set with even just 2-4 languages significantly improves cross-lingual generalization. Our results suggest that building massively multilingual instruction-tuned models can be done with only a very small set of multilingual instruction-responses.
5/22/2024
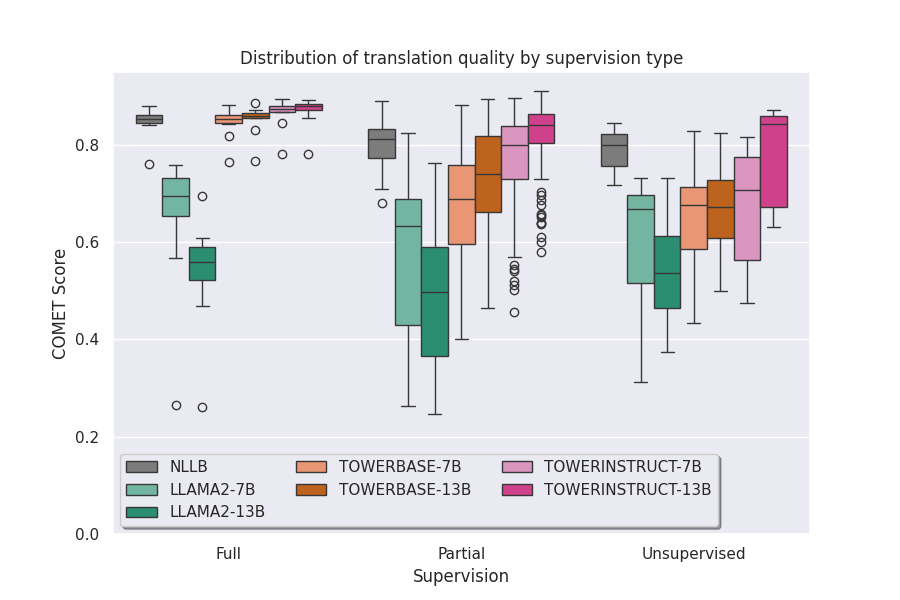
How Multilingual Are Large Language Models Fine-Tuned for Translation?
Aquia Richburg, Marine Carpuat
0
0
A new paradigm for machine translation has recently emerged: fine-tuning large language models (LLM) on parallel text has been shown to outperform dedicated translation systems trained in a supervised fashion on much larger amounts of parallel data (Xu et al., 2024a; Alves et al., 2024). However, it remains unclear whether this paradigm can enable massively multilingual machine translation or whether it requires fine-tuning dedicated models for a small number of language pairs. How does translation fine-tuning impact the MT capabilities of LLMs for zero-shot languages, zero-shot language pairs, and translation tasks that do not involve English? To address these questions, we conduct an extensive empirical evaluation of the translation quality of the TOWER family of language models (Alves et al., 2024) on 132 translation tasks from the multi-parallel FLORES-200 data. We find that translation fine-tuning improves translation quality even for zero-shot languages on average, but that the impact is uneven depending on the language pairs involved. These results call for further research to effectively enable massively multilingual translation with LLMs.
6/3/2024
💬
Eliciting the Translation Ability of Large Language Models via Multilingual Finetuning with Translation Instructions
Jiahuan Li, Hao Zhou, Shujian Huang, Shanbo Cheng, Jiajun Chen
0
0
Large-scale Pretrained Language Models (LLMs), such as ChatGPT and GPT4, have shown strong abilities in multilingual translations, without being explicitly trained on parallel corpora. It is interesting how the LLMs obtain their ability to carry out translation instructions for different languages. In this paper, we present a detailed analysis by finetuning a multilingual pretrained language model, XGLM-7B, to perform multilingual translation following given instructions. Firstly, we show that multilingual LLMs have stronger translation abilities than previously demonstrated. For a certain language, the performance depends on its similarity to English and the amount of data used in the pretraining phase. Secondly, we find that LLMs' ability to carry out translation instructions relies on the understanding of translation instructions and the alignment among different languages. With multilingual finetuning, LLMs could learn to perform the translation task well even for those language pairs unseen during the instruction tuning phase.
4/16/2024
Fine-Tuning Large Language Models to Translate: Will a Touch of Noisy Data in Misaligned Languages Suffice?
Dawei Zhu, Pinzhen Chen, Miaoran Zhang, Barry Haddow, Xiaoyu Shen, Dietrich Klakow
0
0
Traditionally, success in multilingual machine translation can be attributed to three key factors in training data: large volume, diverse translation directions, and high quality. In the current practice of fine-tuning large language models (LLMs) for translation, we revisit the importance of all these factors. We find that LLMs display strong translation capability after being fine-tuned on as few as 32 training instances, and that fine-tuning on a single translation direction effectively enables LLMs to translate in multiple directions. However, the choice of direction is critical: fine-tuning LLMs with English on the target side can lead to task misinterpretation, which hinders translations into non-English languages. A similar problem arises when noise is introduced into the target side of parallel data, especially when the target language is well-represented in the LLM's pre-training. In contrast, noise in an under-represented language has a less pronounced effect. Our findings suggest that attaining successful alignment hinges on teaching the model to maintain a superficial focus, thereby avoiding the learning of erroneous biases beyond translation.
4/23/2024