How You Prompt Matters! Even Task-Oriented Constraints in Instructions Affect LLM-Generated Text Detection

0
🔎
Sign in to get full access
Overview
- The paper explores how task-oriented constraints in instructions can impact the performance of large language model (LLM) generated text detectors.
- Researchers focused on student essay writing as a realistic domain and manually created task-oriented constraints based on factors for essay quality.
- Experiments showed that these constraints can significantly increase the variance in detection performance, making LLM detection more challenging compared to generating texts multiple times or paraphrasing the instruction.
- The analysis suggests that the high instruction-following ability of LLMs is a key factor behind the large impact of such constraints on detection performance.
Plain English Explanation
To catch when large language models (LLMs) are generating fake text, researchers have developed LLM-generated-text detectors that can identify machine-generated content. However, most of these detectors have only been tested on a limited range of text generation instructions.
In this study, the researchers looked at how adding
For example, if a user asked an LLM to write a high-quality student essay, they might include constraints like the essay should have a clear thesis, use relevant evidence, and demonstrate good grammar and style. These constraints are not trying to trick the detector, but are just part of the task the LLM is asked to complete.
The researchers found that even these common, task-oriented constraints can cause a lot of variation in how well the detectors perform. The standard deviation, or spread, of the detector's accuracy scores was much higher (up to 14.4 F1-score) when the LLM was generating text with these constraints, compared to just generating text multiple times or paraphrasing the instructions.
Overall, the researchers observed that these task-oriented constraints tend to make LLM detection more challenging than when no constraints are used. This is because LLMs are very good at closely following the instructions they are given, which allows the constraints to have a big impact on the generated text.
Technical Explanation
The researchers manually created a set of task-oriented constraints for the domain of student essay writing, such as requirements around thesis, evidence, grammar, and style. They then used these constraints to prompt an LLM to generate essay texts and evaluated the performance of several powerful LLM-generated-text detectors on this data.
Experiments showed that the standard deviation (SD) of detector performance on texts generated with task-oriented constraints was significantly higher (up to an SD of 14.4 F1-score) compared to texts generated multiple times or with paraphrased instructions. This indicates that the constraints can introduce much more variability in detector performance than other factors.
The researchers also observed an overall trend where the constraints made LLM detection more challenging than without them. They attribute this to the high instruction-following ability of LLMs, which allows the task-oriented constraints to have a large impact on the generated text and, in turn, the detector's ability to identify it as machine-generated.
Critical Analysis
The paper highlights an important limitation of current LLM-generated-text detectors - they may not perform as well in real-world scenarios where users provide diverse, task-oriented instructions to LLMs. While most existing detectors are trained on a limited set of generation patterns, this research shows that even common, non-adversarial constraints can significantly degrade detector performance.
One potential area for further research is exploring more robust detector architectures or training approaches that can better handle diverse instruction patterns, including combinatorial optimization prompts and instruction-tuning techniques. Additionally, the need for more structured, user-centric datasets is highlighted, as current benchmarks may not capture the full range of real-world text generation scenarios.
While the paper focuses on student essay writing, the findings likely extend to other domains where users provide detailed instructions to LLMs, such as premium instruction-tuning data. Addressing the challenge of task-oriented constraints will be crucial for developing LLM-generated-text detectors that are robust and reliable in practical applications.
Conclusion
This research reveals a significant limitation in the performance of current LLM-generated-text detectors when faced with task-oriented constraints in user instructions. The high instruction-following ability of LLMs allows even common, non-adversarial constraints to have a large impact on the generated text, leading to much greater variability in detector accuracy.
These findings highlight the need for more robust detector architectures and training approaches that can better handle diverse real-world text generation scenarios. Additionally, the development of more structured, user-centric datasets will be crucial for advancing the state of the art in LLM-generated-text detection.
As LLMs become more widely deployed, ensuring the reliability and trustworthiness of their outputs will be critical. This research provides important insights into the challenges that must be addressed to make LLM-generated-text detectors truly effective in practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔎
0
How You Prompt Matters! Even Task-Oriented Constraints in Instructions Affect LLM-Generated Text Detection
Ryuto Koike, Masahiro Kaneko, Naoaki Okazaki
To combat the misuse of Large Language Models (LLMs), many recent studies have presented LLM-generated-text detectors with promising performance. When users instruct LLMs to generate texts, the instruction can include different constraints depending on the user's need. However, most recent studies do not cover such diverse instruction patterns when creating datasets for LLM detection. In this paper, we reveal that even task-oriented constraints -- constraints that would naturally be included in an instruction and are not related to detection-evasion -- cause existing powerful detectors to have a large variance in detection performance. We focus on student essay writing as a realistic domain and manually create task-oriented constraints based on several factors for essay quality. Our experiments show that the standard deviation (SD) of current detector performance on texts generated by an instruction with such a constraint is significantly larger (up to an SD of 14.4 F1-score) than that by generating texts multiple times or paraphrasing the instruction. We also observe an overall trend where the constraints can make LLM detection more challenging than without them. Finally, our analysis indicates that the high instruction-following ability of LLMs fosters the large impact of such constraints on detection performance.
Read more6/13/2024

0
Unlocking Anticipatory Text Generation: A Constrained Approach for Large Language Models Decoding
Lifu Tu, Semih Yavuz, Jin Qu, Jiacheng Xu, Rui Meng, Caiming Xiong, Yingbo Zhou
Large Language Models (LLMs) have demonstrated a powerful ability for text generation. However, achieving optimal results with a given prompt or instruction can be challenging, especially for billion-sized models. Additionally, undesired behaviors such as toxicity or hallucinations can manifest. While much larger models (e.g., ChatGPT) may demonstrate strength in mitigating these issues, there is still no guarantee of complete prevention. In this work, we propose formalizing text generation as a future-constrained generation problem to minimize undesirable behaviors and enforce faithfulness to instructions. The estimation of future constraint satisfaction, accomplished using LLMs, guides the text generation process. Our extensive experiments demonstrate the effectiveness of the proposed approach across three distinct text generation tasks: keyword-constrained generation (Lin et al., 2020), toxicity reduction (Gehman et al., 2020), and factual correctness in question-answering (Gao et al., 2023).
Read more6/27/2024
0
Open (Clinical) LLMs are Sensitive to Instruction Phrasings
Alberto Mario Ceballos Arroyo, Monica Munnangi, Jiuding Sun, Karen Y. C. Zhang, Denis Jered McInerney, Byron C. Wallace, Silvio Amir
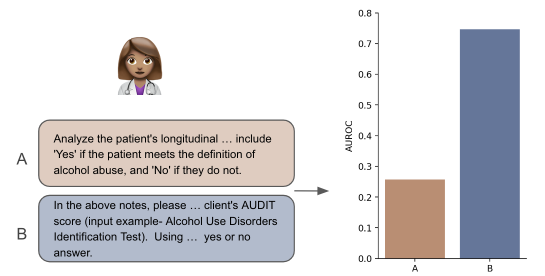
Instruction-tuned Large Language Models (LLMs) can perform a wide range of tasks given natural language instructions to do so, but they are sensitive to how such instructions are phrased. This issue is especially concerning in healthcare, as clinicians are unlikely to be experienced prompt engineers and the potential consequences of inaccurate outputs are heightened in this domain. This raises a practical question: How robust are instruction-tuned LLMs to natural variations in the instructions provided for clinical NLP tasks? We collect prompts from medical doctors across a range of tasks and quantify the sensitivity of seven LLMs -- some general, others specialized -- to natural (i.e., non-adversarial) instruction phrasings. We find that performance varies substantially across all models, and that -- perhaps surprisingly -- domain-specific models explicitly trained on clinical data are especially brittle, compared to their general domain counterparts. Further, arbitrary phrasing differences can affect fairness, e.g., valid but distinct instructions for mortality prediction yield a range both in overall performance, and in terms of differences between demographic groups.
Read more7/15/2024

0
Large Language Models Might Not Care What You Are Saying: Prompt Format Beats Descriptions
Chenming Tang, Zhixiang Wang, Yunfang Wu
With the help of in-context learning (ICL), large language models (LLMs) have achieved impressive performance across various tasks. However, the function of descriptive instructions during ICL remains under-explored. In this work, we propose an ensemble prompt framework to describe the selection criteria of multiple in-context examples, and preliminary experiments on machine translation (MT) across six translation directions confirm that this framework boosts ICL perfromance. But to our surprise, LLMs might not necessarily care what the descriptions actually say, and the performance gain is primarily caused by the ensemble format, since the framework could lead to improvement even with random descriptive nouns. We further apply this new ensemble prompt on a range of commonsense, math, logical reasoning and hallucination tasks with three LLMs and achieve promising results, suggesting again that designing a proper prompt format would be much more effective and efficient than paying effort into specific descriptions. Our code will be publicly available once this paper is published.
Read more8/23/2024