Monotonic Paraphrasing Improves Generalization of Language Model Prompting

0
Sign in to get full access
Overview
- The paper explores a technique called "monotonic paraphrasing" to improve the generalization of language model prompting.
- Monotonic paraphrasing involves generating paraphrases of a prompt that preserve the original meaning and order of the input text.
- The authors hypothesize that this approach can help language models better understand the intent behind prompts, leading to improved performance on downstream tasks.
Plain English Explanation
The researchers in this paper looked at a way to help language models, like the ones used in chatbots and digital assistants, understand prompts (the text you give them to respond to) better. They call this technique "monotonic paraphrasing."
Monotonic paraphrasing involves taking a prompt and generating new versions of it that say the same thing, but in different words. Importantly, the new versions keep the same order and meaning as the original prompt.
The key idea is that by seeing multiple paraphrased versions of a prompt, the language model can better grasp the underlying intent or goal of the prompt. This, in turn, helps the model provide more relevant and useful responses when people use it.
For example, if the original prompt was "Describe the weather today," the monotonic paraphrases might be:
- "What is the current weather condition?"
- "Give me an overview of today's meteorological state."
By seeing these alternative phrasings, the language model can better understand that the user simply wants a description of the weather, rather than getting caught up on the specific wording of the prompt.
Deconstructing context: Learning understanding prompts via corruption is another approach that tries to help models grasp prompt intent, but the monotonic paraphrasing technique is novel and the researchers think it has some advantages.
Technical Explanation
The paper proposes a novel technique called "monotonic paraphrasing" to improve the generalization of language model prompting. Monotonic paraphrasing involves generating paraphrased versions of a given prompt that preserve the original meaning and order of the input text.
The authors hypothesize that exposing language models to these monotonically paraphrased prompts during training can help the models better understand the underlying intent behind prompts, leading to improved performance on downstream tasks.
To test this, the researchers conducted experiments on several benchmark language understanding tasks. They compared models trained with standard prompts to those trained with monotonically paraphrased prompts. The results showed that the monotonic paraphrasing approach led to significant improvements in generalization across the evaluated tasks.
The paper also provides insights into the characteristics of effective monotonic paraphrases. The authors find that paraphrases that maintain lexical and syntactic similarity to the original prompt tend to be most useful for improving model performance.
Plug & Play Prompts: A Prompt-Tuning Approach for Controlling Language Models and Progressive Multi-Modal Conditional Prompt Tuning are other works that explore techniques for improving prompt-based language model control, but the monotonic paraphrasing approach presented in this paper is a novel contribution.
Critical Analysis
The paper provides a compelling argument for the benefits of monotonic paraphrasing in improving language model generalization. The experimental results demonstrate the effectiveness of this technique across multiple benchmark tasks.
However, the paper does not delve deeply into the potential limitations or caveats of the approach. For example, it would be interesting to understand how the monotonic paraphrasing technique scales to longer or more complex prompts, or how it might perform on more open-ended or creative language tasks.
Additionally, the paper focuses primarily on the prompting stage and does not explore how monotonic paraphrasing could be combined with other techniques, such as low-resource machine translation through retrieval augmented generation, to further improve language model performance.
Overall, the research presented in this paper is a valuable contribution to the field of prompt-based language model control and understanding. However, further exploration of the limitations and potential synergies with other techniques could provide additional insights and avenues for future research.
Conclusion
The paper introduces a novel technique called "monotonic paraphrasing" that can improve the generalization of language model prompting. By generating paraphrased versions of prompts that preserve the original meaning and order, the authors demonstrate that language models can better understand the underlying intent behind prompts, leading to improved performance on downstream tasks.
This research represents an important step forward in the ongoing effort to enhance the capabilities and robustness of language models, which are increasingly becoming integral components of various AI-powered applications and services. By continuing to explore techniques like monotonic paraphrasing, researchers can help ensure that these models are able to reliably and effectively understand and respond to user prompts, ultimately improving the user experience and the real-world applicability of language-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Monotonic Paraphrasing Improves Generalization of Language Model Prompting
Qin Liu, Fei Wang, Nan Xu, Tianyi Yan, Tao Meng, Muhao Chen
Performance of large language models (LLMs) may vary with different prompts or instructions of even the same task. One commonly recognized factor for this phenomenon is the model's familiarity with the given prompt or instruction, which is typically estimated by its perplexity. However, finding the prompt with the lowest perplexity is challenging, given the enormous space of possible prompting phrases. In this paper, we propose monotonic paraphrasing (MonoPara), an end-to-end decoding strategy that paraphrases given prompts or instructions into their lower perplexity counterparts based on an ensemble of a paraphrase LM for prompt (or instruction) rewriting, and a target LM (i.e. the prompt or instruction executor) that constrains the generation for lower perplexity. The ensemble decoding process can efficiently paraphrase the original prompt without altering its semantic meaning, while monotonically decreasing the perplexity of each generation as calculated by the target LM. We explore in detail both greedy and search-based decoding as two alternative decoding schemes of MonoPara. Notably, MonoPara does not require any training and can monotonically lower the perplexity of the paraphrased prompt or instruction, leading to improved performance of zero-shot LM prompting as evaluated on a wide selection of tasks. In addition, MonoPara is also shown to effectively improve LMs' generalization on perturbed and unseen task instructions.
Read more4/19/2024
💬
0
New!Demystifying Prompts in Language Models via Perplexity Estimation
Hila Gonen, Srini Iyer, Terra Blevins, Noah A. Smith, Luke Zettlemoyer
Language models can be prompted to perform a wide variety of zero- and few-shot learning problems. However, performance varies significantly with the choice of prompt, and we do not yet understand why this happens or how to pick the best prompts. In this work, we analyze the factors that contribute to this variance and establish a new empirical hypothesis: the performance of a prompt is coupled with the extent to which the model is familiar with the language it contains. Over a wide range of tasks, we show that the lower the perplexity of the prompt is, the better the prompt is able to perform the task. As a result, we devise a method for creating prompts: (1) automatically extend a small seed set of manually written prompts by paraphrasing using GPT3 and backtranslation and (2) choose the lowest perplexity prompts to get significant gains in performance.
Read more9/16/2024

0
Multi-Prompting Decoder Helps Better Language Understanding
Zifeng Cheng, Zhaoling Chen, Zhiwei Jiang, Yafeng Yin, Shiping Ge, Yuliang Liu, Qing Gu
Recent Pre-trained Language Models (PLMs) usually only provide users with the inference APIs, namely the emerging Model-as-a-Service (MaaS) setting. To adapt MaaS PLMs to downstream tasks without accessing their parameters and gradients, some existing methods focus on the output-side adaptation of PLMs, viewing the PLM as an encoder and then optimizing a task-specific decoder for decoding the output hidden states and class scores of the PLM. Despite the effectiveness of these methods, they only use a single prompt to query PLMs for decoding, leading to a heavy reliance on the quality of the adopted prompt. In this paper, we propose a simple yet effective Multi-Prompting Decoder (MPD) framework for MaaS adaptation. The core idea is to query PLMs with multiple different prompts for each sample, thereby obtaining multiple output hidden states and class scores for subsequent decoding. Such multi-prompting decoding paradigm can simultaneously mitigate reliance on the quality of a single prompt, alleviate the issue of data scarcity under the few-shot setting, and provide richer knowledge extracted from PLMs. Specifically, we propose two decoding strategies: multi-prompting decoding with optimal transport for hidden states and calibrated decoding for class scores. Extensive experiments demonstrate that our method achieves new state-of-the-art results on multiple natural language understanding datasets under the few-shot setting.
Read more6/11/2024
0
Paraphrase Types Elicit Prompt Engineering Capabilities
Jan Philip Wahle, Terry Ruas, Yang Xu, Bela Gipp
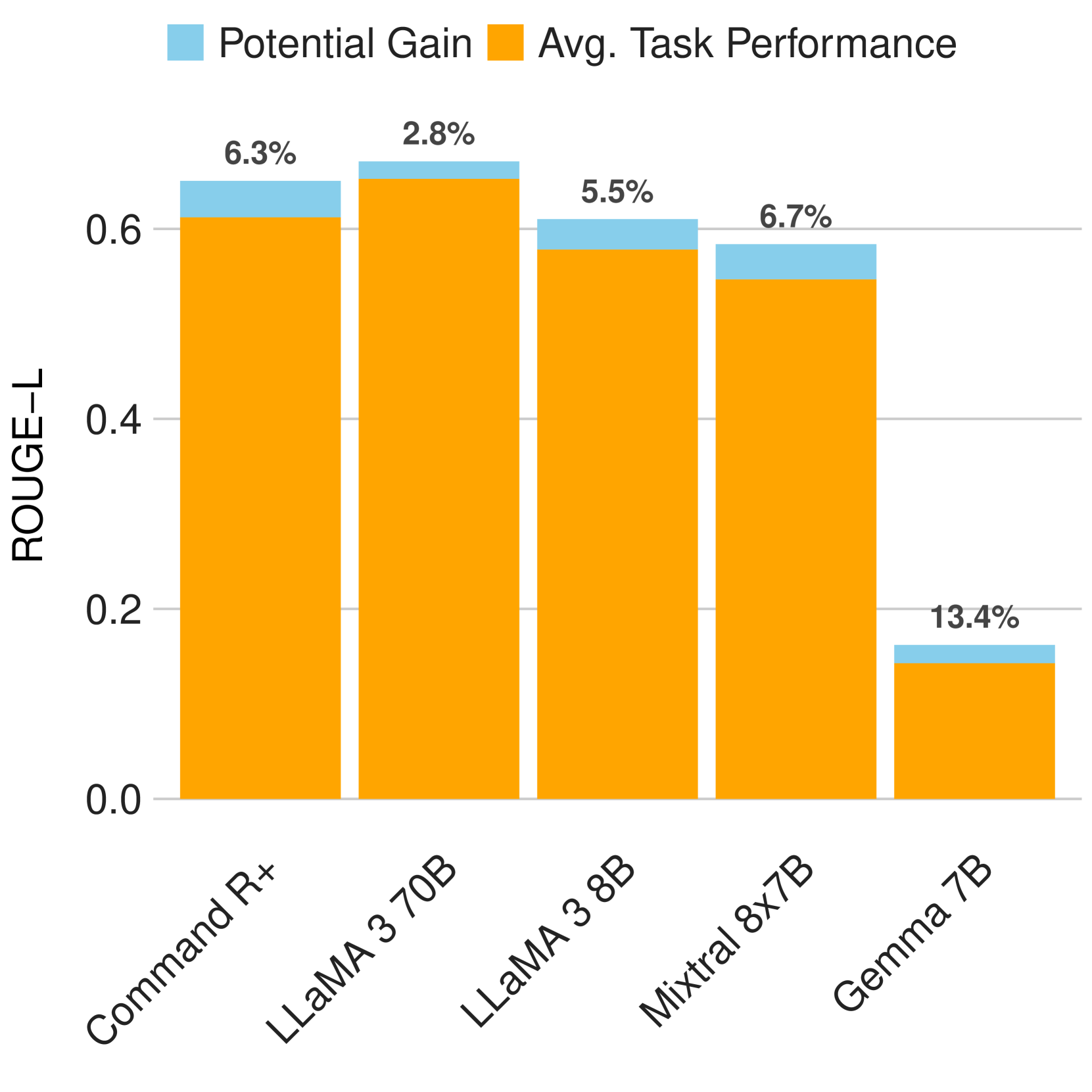
Much of the success of modern language models depends on finding a suitable prompt to instruct the model. Until now, it has been largely unknown how variations in the linguistic expression of prompts affect these models. This study systematically and empirically evaluates which linguistic features influence models through paraphrase types, i.e., different linguistic changes at particular positions. We measure behavioral changes for five models across 120 tasks and six families of paraphrases (i.e., morphology, syntax, lexicon, lexico-syntax, discourse, and others). We also control for other prompt engineering factors (e.g., prompt length, lexical diversity, and proximity to training data). Our results show a potential for language models to improve tasks when their prompts are adapted in specific paraphrase types (e.g., 6.7% median gain in Mixtral 8x7B; 5.5% in LLaMA 3 8B). In particular, changes in morphology and lexicon, i.e., the vocabulary used, showed promise in improving prompts. These findings contribute to developing more robust language models capable of handling variability in linguistic expression.
Read more7/1/2024