Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models

0

Sign in to get full access
Overview
- This paper explores the use of self-training techniques to scale problem-solving capabilities of large language models beyond the limits of human-annotated data.
- The researchers propose a novel Expectation-Maximization (EM) approach for reinforced self-training, which iteratively refines the model's problem-solving abilities.
- The paper demonstrates the effectiveness of this method on a range of tasks, including mathematical reasoning, symbolic manipulation, and natural language inference.
Plain English Explanation
The paper explores a way to help large language models (LLMs) like GPT-3 and ChatGLM become better at solving problems, even when they don't have access to a lot of human-labeled training data.
The researchers developed a new technique called "reinforced self-training" that allows the models to keep improving themselves. Here's how it works:
- The model is first trained on a limited set of human-annotated data, just like usual.
- Then, the model is given a bunch of unlabeled problems to solve on its own.
- The model's own solutions are used to "reinforce" its learning - the model gets feedback on whether its solutions are correct or not, and it can use that information to get better over time.
- This self-training process is guided by an Expectation-Maximization (EM) algorithm, which helps the model gradually refine its problem-solving abilities.
The paper shows that this approach allows the models to significantly outperform their initial capabilities on a variety of tasks, including math, symbolic manipulation, and natural language reasoning. The key idea is to let the models learn from their own experiences, rather than being limited by the available human-annotated data.
Technical Explanation
The paper introduces a novel Expectation-Maximization (EM) approach for reinforced self-training of large language models. The core idea is to iteratively refine the model's problem-solving abilities by having it solve unlabeled problems and then use its own solutions to provide feedback and guide further learning.
Specifically, the EM algorithm consists of two steps:
- Expectation step: The model is used to generate solutions for a set of unlabeled problems. These solutions are then evaluated using a reward function to determine their quality.
- Maximization step: The model's parameters are updated to maximize the expected reward from the solutions generated in the Expectation step.
This process is repeated, with the model's performance gradually improving as it learns from its own experiences. The researchers demonstrate the effectiveness of this approach on a range of tasks, including mathematical reasoning, symbolic manipulation, and natural language inference.
For example, on the MATH dataset, the self-trained model achieved a 24% relative improvement in accuracy compared to the baseline model trained only on human-annotated data. Similarly, on the ANLI dataset for natural language inference, the self-trained model showed a 10% relative improvement.
The key innovation of this work is the use of EM-based self-training to scale the problem-solving abilities of language models beyond the limits of human-annotated data. This approach aligns with the broader trend of leveraging large language models for task-specific alignment and evaluating their general capabilities.
Critical Analysis
The paper provides a compelling approach for scaling the problem-solving capabilities of large language models through self-training. However, there are a few potential limitations and areas for further research:
- Generalization beyond the training distribution: While the self-training process allows the models to improve within the distribution of problems encountered during training, it's unclear how well the models would generalize to novel problem types or out-of-distribution scenarios.
- Computational efficiency: The iterative EM-based self-training process can be computationally intensive, especially for large-scale models. Exploring more efficient optimization techniques could be an area for future work.
- Robustness and reliability: The paper does not address potential issues with the reliability and robustness of the self-trained models, such as their susceptibility to adversarial attacks or their ability to provide well-calibrated uncertainty estimates.
Overall, the paper presents a promising approach for enhancing the problem-solving capabilities of large language models, but more research is needed to address these potential limitations and ensure the practical deployment of such techniques.
Conclusion
This paper introduces a novel Expectation-Maximization (EM) approach for reinforced self-training of large language models, which allows them to scale their problem-solving abilities beyond the limits of human-annotated data. The key innovation is the iterative process of having the models solve unlabeled problems, evaluate their own solutions, and use that feedback to improve their performance over time.
The results demonstrate the effectiveness of this approach on a range of tasks, including mathematical reasoning, symbolic manipulation, and natural language inference. This work aligns with the broader trends in the field of using large language models for task-specific alignment and evaluating their general capabilities.
While the paper presents a compelling solution, further research is needed to address potential limitations, such as the model's ability to generalize beyond the training distribution, the computational efficiency of the self-training process, and the robustness and reliability of the self-trained models. Nonetheless, this paper represents an important step towards scaling the problem-solving capabilities of large language models through self-training techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri Hron, Kathleen Kenealy, Kevin Swersky, Kshiteej Mahajan, Laura Culp, Lechao Xiao, Maxwell L. Bileschi, Noah Constant, Roman Novak, Rosanne Liu, Tris Warkentin, Yundi Qian, Yamini Bansal, Ethan Dyer, Behnam Neyshabur, Jascha Sohl-Dickstein, Noah Fiedel
Fine-tuning language models~(LMs) on human-generated data remains a prevalent practice. However, the performance of such models is often limited by the quantity and diversity of high-quality human data. In this paper, we explore whether we can go beyond human data on tasks where we have access to scalar feedback, for example, on math problems where one can verify correctness. To do so, we investigate a simple self-training method based on expectation-maximization, which we call ReST$^{EM}$, where we (1) generate samples from the model and filter them using binary feedback, (2) fine-tune the model on these samples, and (3) repeat this process a few times. Testing on advanced MATH reasoning and APPS coding benchmarks using PaLM-2 models, we find that ReST$^{EM}$ scales favorably with model size and significantly surpasses fine-tuning only on human data. Overall, our findings suggest self-training with feedback can substantially reduce dependence on human-generated data.
Read more4/19/2024

0
Self-training Language Models for Arithmetic Reasoning
Marek Kadlv{c}'ik, Michal v{S}tef'anik
Language models achieve impressive results in tasks involving complex multistep reasoning, but scaling these capabilities further traditionally requires expensive collection of more annotated data. In this work, we explore the potential of improving the capabilities of language models without new data, merely using automated feedback to the validity of their predictions in arithmetic reasoning (self-training). We find that models can substantially improve in both single-round (offline) and online self-training. In the offline setting, supervised methods are able to deliver gains comparable to preference optimization, but in online self-training, preference optimization shows to largely outperform supervised training thanks to superior stability and robustness on unseen types of problems.
Read more7/12/2024
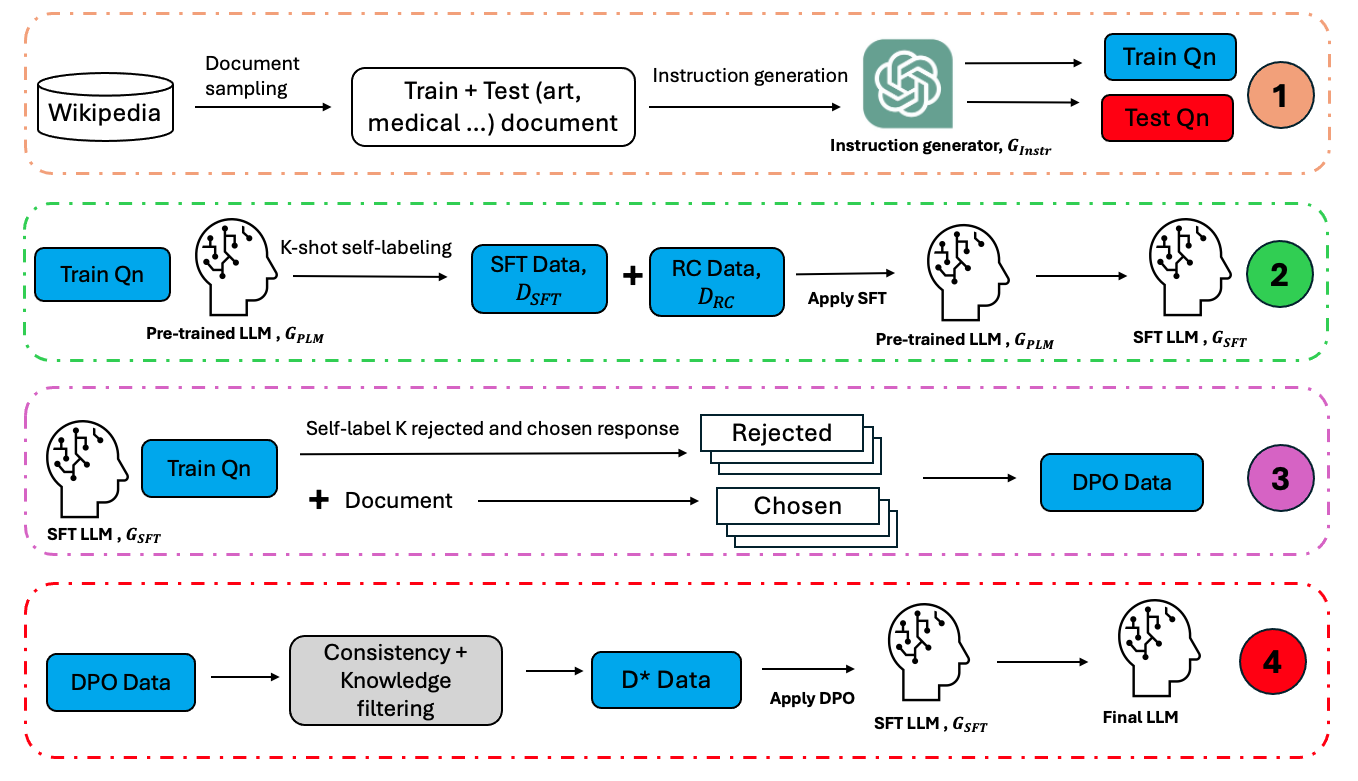
0
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
Read more6/18/2024
💬
0
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Bingxiang He, Wei Zhu, Yuan Ni, Guotong Xie, Ruobing Xie, Yankai Lin, Zhiyuan Liu, Maosong Sun
Learning from human feedback has become a pivot technique in aligning large language models (LLMs) with human preferences. However, acquiring vast and premium human feedback is bottlenecked by time, labor, and human capability, resulting in small sizes or limited topics of current datasets. This further hinders feedback learning as well as alignment research within the open-source community. To address this issue, we explore how to go beyond human feedback and collect high-quality textit{AI feedback} automatically for a scalable alternative. Specifically, we identify textbf{scale and diversity} as the key factors for feedback data to take effect. Accordingly, we first broaden instructions and responses in both amount and breadth to encompass a wider range of user-assistant interactions. Then, we meticulously apply a series of techniques to mitigate annotation biases for more reliable AI feedback. We finally present textsc{UltraFeedback}, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon textsc{UltraFeedback}, we align a LLaMA-based model by best-of-$n$ sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks. Our work validates the effectiveness of scaled AI feedback data in constructing strong open-source chat language models, serving as a solid foundation for future feedback learning research. Our data and models are available at https://github.com/thunlp/UltraFeedback.
Read more7/17/2024