MathScape: Evaluating MLLMs in multimodal Math Scenarios through a Hierarchical Benchmark

0

Sign in to get full access
Overview
- Introduces MathScape, a hierarchical benchmark for evaluating multimodal large language models (MLLMs) on math-related tasks
- Covers a range of mathematical scenarios, from simple arithmetic to complex problem-solving
- Aims to provide a comprehensive assessment of an MLLM's capabilities in the math domain
Plain English Explanation
MathScape is a new evaluation benchmark that allows researchers to test how well multimodal large language models (MLLMs) perform on a variety of math-related tasks. MLLMs are AI systems that can understand and generate text, images, and other types of data, making them potentially useful for math applications.
The MathScape benchmark covers a wide range of mathematical scenarios, from basic arithmetic to more complex problem-solving. This hierarchical structure means the benchmark starts with simpler tasks and gradually becomes more challenging, allowing researchers to get a more detailed understanding of an MLLM's math capabilities.
By using this comprehensive multimodal math evaluation approach, the researchers hope to provide a better way to assess how well MLLMs can handle math-related tasks. This could be useful for developing AI systems that can assist humans with math-heavy work, such as engineering, finance, or scientific research.
Technical Explanation
The key elements of the MathScape benchmark include:
-
Hierarchical Structure: The benchmark is organized into a hierarchical structure, with tasks ranging from simple arithmetic to more complex mathematical problem-solving. This allows for a granular evaluation of an MLLM's capabilities.
-
Multimodal Inputs: The benchmark includes a variety of input formats, such as text, images, and mathematical notation. This tests an MLLM's ability to understand and reason about math in a multimodal context, as opposed to just text-based math problems.
-
Diverse Mathematical Scenarios: The benchmark covers a wide range of mathematical topics, from basic arithmetic to advanced concepts like geometry, algebra, and calculus. This breadth of coverage provides a comprehensive assessment of an MLLM's math proficiency.
-
Evaluation Metrics: The benchmark uses a range of metrics to assess MLLM performance, including accuracy, step-by-step reasoning, and the ability to generate relevant explanations. This allows for a nuanced evaluation of an MLLM's capabilities.
The researchers tested several state-of-the-art MLLMs on the MathScape benchmark and found that while these models showed promising performance on some math tasks, they struggled with more complex problem-solving and reasoning. This highlights the need for continued research and development to improve the math capabilities of MLLMs.
Critical Analysis
The MathScape benchmark is a valuable contribution to the field of multimodal AI research, as it provides a comprehensive and standardized way to evaluate MLLM performance on math-related tasks. However, the researchers acknowledge that the benchmark has some limitations:
-
Task Diversity: While the benchmark covers a wide range of mathematical scenarios, there may be additional task types or mathematical concepts that are not currently included.
-
Benchmark Size: The current version of the benchmark may be limited in size, which could impact the statistical significance of the results.
-
Real-World Applicability: The researchers note that the tasks in the benchmark may not fully capture the complexity and nuance of real-world math problems that MLLMs would need to solve.
Future research could address these limitations by expanding the benchmark, exploring additional evaluation metrics, and investigating the real-world applicability of MLLM performance on the MathScape tasks.
Conclusion
The MathScape benchmark represents an important step forward in the evaluation of multimodal large language models for math-related tasks. By providing a comprehensive and hierarchical assessment, the benchmark can help researchers and developers identify the strengths and weaknesses of current MLLM systems, and guide future research and development efforts to improve their mathematical capabilities. As AI systems become increasingly integrated into math-heavy domains, tools like MathScape will be crucial for ensuring that these systems can reliably and accurately assist humans in solving complex mathematical problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MathScape: Evaluating MLLMs in multimodal Math Scenarios through a Hierarchical Benchmark
Minxuan Zhou, Hao Liang, Tianpeng Li, Zhiyu Wu, Mingan Lin, Linzhuang Sun, Yaqi Zhou, Yan Zhang, Xiaoqin Huang, Yicong Chen, Yujing Qiao, Weipeng Chen, Bin Cui, Wentao Zhang, Zenan Zhou
With the development of Multimodal Large Language Models (MLLMs), the evaluation of multimodal models in the context of mathematical problems has become a valuable research field. Multimodal visual-textual mathematical reasoning serves as a critical indicator for evaluating the comprehension and complex multi-step quantitative reasoning abilities of MLLMs. However, previous multimodal math benchmarks have not sufficiently integrated visual and textual information. To address this gap, we proposed MathScape, a new benchmark that emphasizes the understanding and application of combined visual and textual information. MathScape is designed to evaluate photo-based math problem scenarios, assessing the theoretical understanding and application ability of MLLMs through a categorical hierarchical approach. We conduct a multi-dimensional evaluation on 11 advanced MLLMs, revealing that our benchmark is challenging even for the most sophisticated models. By analyzing the evaluation results, we identify the limitations of MLLMs, offering valuable insights for enhancing model performance.
Read more8/26/2024
0
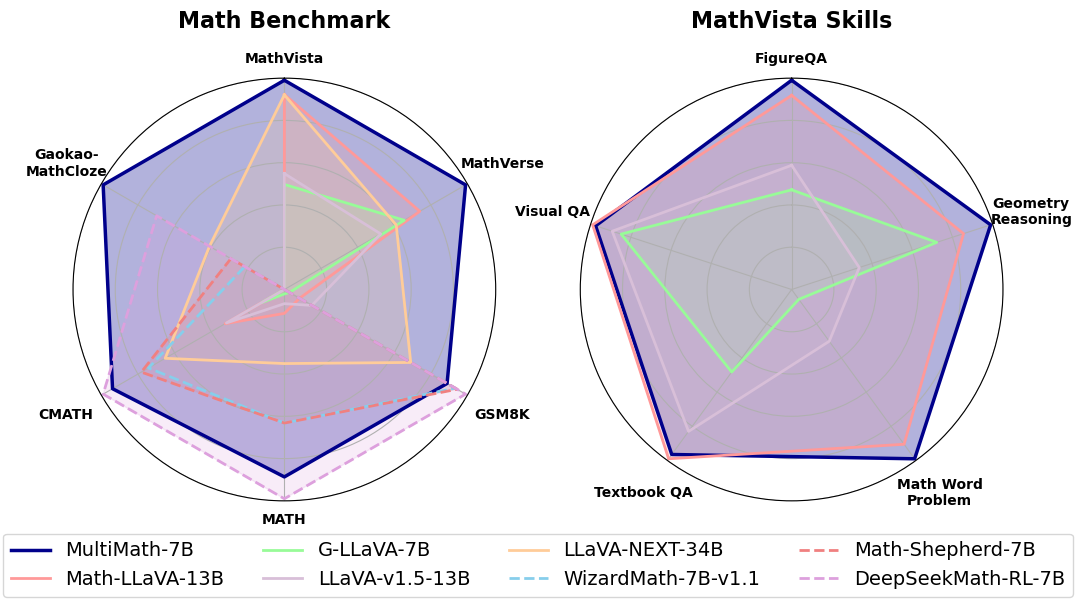
MultiMath: Bridging Visual and Mathematical Reasoning for Large Language Models
Shuai Peng, Di Fu, Liangcai Gao, Xiuqin Zhong, Hongguang Fu, Zhi Tang
The rapid development of large language models (LLMs) has spurred extensive research into their domain-specific capabilities, particularly mathematical reasoning. However, most open-source LLMs focus solely on mathematical reasoning, neglecting the integration with visual injection, despite the fact that many mathematical tasks rely on visual inputs such as geometric diagrams, charts, and function plots. To fill this gap, we introduce textbf{MultiMath-7B}, a multimodal large language model that bridges the gap between math and vision. textbf{MultiMath-7B} is trained through a four-stage process, focusing on vision-language alignment, visual and math instruction-tuning, and process-supervised reinforcement learning. We also construct a novel, diverse and comprehensive multimodal mathematical dataset, textbf{MultiMath-300K}, which spans K-12 levels with image captions and step-wise solutions. MultiMath-7B achieves state-of-the-art (SOTA) performance among open-source models on existing multimodal mathematical benchmarks and also excels on text-only mathematical benchmarks. Our model and dataset are available at {textcolor{blue}{url{https://github.com/pengshuai-rin/MultiMath}}}.
Read more9/4/2024

0
MathVerse: Does Your Multi-modal LLM Truly See the Diagrams in Visual Math Problems?
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Peng Gao, Hongsheng Li
The remarkable progress of Multi-modal Large Language Models (MLLMs) has garnered unparalleled attention, due to their superior performance in visual contexts. However, their capabilities in visual math problem-solving remain insufficiently evaluated and understood. We investigate current benchmarks to incorporate excessive visual content within textual questions, which potentially assist MLLMs in deducing answers without truly interpreting the input diagrams. To this end, we introduce MathVerse, an all-around visual math benchmark designed for an equitable and in-depth evaluation of MLLMs. We meticulously collect 2,612 high-quality, multi-subject math problems with diagrams from publicly available sources. Each problem is then transformed by human annotators into six distinct versions, each offering varying degrees of information content in multi-modality, contributing to 15K test samples in total. This approach allows MathVerse to comprehensively assess whether and how much MLLMs can truly understand the visual diagrams for mathematical reasoning. In addition, we propose a Chain-of-Thought (CoT) evaluation strategy for a fine-grained assessment of the output answers. Rather than naively judging True or False, we employ GPT-4(V) to adaptively extract crucial reasoning steps, and then score each step with detailed error analysis, which can reveal the intermediate CoT reasoning quality by MLLMs. We hope the MathVerse benchmark may provide unique insights to guide the future development of MLLMs. Project page: https://mathverse-cuhk.github.io
Read more8/20/2024

0
A Survey on Benchmarks of Multimodal Large Language Models
Jian Li, Weiheng Lu, Hao Fei, Meng Luo, Ming Dai, Min Xia, Yizhang Jin, Zhenye Gan, Ding Qi, Chaoyou Fu, Ying Tai, Wankou Yang, Yabiao Wang, Chengjie Wang
Multimodal Large Language Models (MLLMs) are gaining increasing popularity in both academia and industry due to their remarkable performance in various applications such as visual question answering, visual perception, understanding, and reasoning. Over the past few years, significant efforts have been made to examine MLLMs from multiple perspectives. This paper presents a comprehensive review of 200 benchmarks and evaluations for MLLMs, focusing on (1)perception and understanding, (2)cognition and reasoning, (3)specific domains, (4)key capabilities, and (5)other modalities. Finally, we discuss the limitations of the current evaluation methods for MLLMs and explore promising future directions. Our key argument is that evaluation should be regarded as a crucial discipline to support the development of MLLMs better. For more details, please visit our GitHub repository: https://github.com/swordlidev/Evaluation-Multimodal-LLMs-Survey.
Read more9/9/2024