Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph

0
Sign in to get full access
Overview
- This paper explores the evolution of latent representations in large language models (LLMs) over time, using a temporal knowledge graph approach.
- The authors investigate how the internal representations of LLMs change as they are trained on more data, and how these changes relate to the models' performance on various tasks.
- The research provides insights into the inner workings of LLMs and how their knowledge and reasoning capabilities develop during the training process.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at tasks like generating human-like text, answering questions, and even performing complex reasoning. However, the inner workings of these models can be difficult to understand. This paper aims to shed light on how the knowledge and capabilities of LLMs evolve as they are trained on more and more data.
The researchers used a technique called a "temporal knowledge graph" to track the changes in the latent representations (the internal encodings) of an LLM over time. This allowed them to see how the model's understanding of various concepts and their relationships developed as it learned from more examples.
By analyzing these changes, the authors were able to gain insights into how LLMs acquire and organize knowledge. For example, they found that the models first learn basic facts and relationships, and then gradually build more complex and nuanced understandings. The researchers also looked at how the models' performance on different tasks, like answering questions or solving problems, is related to the evolution of their internal representations.
Overall, this work provides a valuable window into the "black box" of large language models, helping us better understand how these powerful AI systems work and how they can be improved in the future. The findings could also have implications for how we use LLMs as assistants and how we evaluate their truthfulness and reasoning abilities.
Technical Explanation
The core of this research is the use of a temporal knowledge graph (TKG) to track the evolution of latent representations in a large language model (LLM) over the course of its training. A TKG is a data structure that represents entities (concepts) and the relationships between them, with the added dimension of time.
The authors trained an LLM on a large corpus of text data and periodically captured snapshots of the model's internal representations. They then used these snapshots to construct a TKG, with the entities representing the concepts learned by the model and the relationships representing how those concepts are connected.
By analyzing the changes in the TKG over time, the researchers were able to gain insights into how the LLM's understanding of the world evolves. For example, they observed that the model first learns basic facts and simple relationships, and then gradually builds more complex and nuanced knowledge as it is exposed to more data.
The authors also looked at how the changes in the LLM's latent representations relate to its performance on various tasks, such as question answering and problem-solving. They found that the evolution of the model's internal representations is closely tied to its ability to reason and solve problems.
Overall, this work provides a novel approach to understanding the inner workings of large language models, and could have important implications for how these models are used as cross-modal and cross-lingual assistants in the future.
Critical Analysis
The research presented in this paper is a valuable contribution to our understanding of large language models, but it also has some limitations and potential areas for further exploration.
One potential concern is the scope of the analysis, which is limited to a single LLM trained on a specific corpus of data. While the authors' findings provide important insights, it would be valuable to see if the same patterns hold true for other models and datasets. Expanding the research to a broader range of LLMs and domains could help validate the generalizability of the results.
Additionally, the paper does not delve deeply into the potential biases or ethical considerations that may arise from the way LLMs acquire and organize knowledge. As these models become more prominent in various applications, it will be crucial to thoroughly investigate such issues and ensure that they are developed and deployed responsibly.
Further research could also explore the relationship between the evolution of latent representations and the models' capabilities in more detail. For example, the authors could investigate whether there are specific "tipping points" in the development of the LLM's internal representations that correspond to significant breakthroughs in its performance on different tasks.
Overall, this paper represents an important step forward in understanding the inner workings of large language models, but there is still much more work to be done in this area. Continued research and critical analysis will be essential for ensuring that these powerful AI systems are developed and used in ways that are beneficial to society.
Conclusion
This research paper provides a novel approach to studying the evolution of large language models (LLMs) by using a temporal knowledge graph to track changes in their internal representations over time. The findings offer valuable insights into how LLMs acquire and organize knowledge, and how these changes relate to the models' performance on various tasks.
The work has important implications for our understanding of these powerful AI systems, as well as their potential applications as assistants in a variety of domains. By shedding light on the "black box" of LLMs, this research could pave the way for more transparent and accountable development of these technologies, ensuring that they are used in ways that are beneficial to society.
While the paper presents a promising approach, it also highlights the need for further research to validate the findings across a wider range of models and datasets, and to explore the ethical considerations associated with the development and deployment of large language models. As these AI systems become increasingly influential, it will be crucial to maintain a critical and thoughtful perspective on their capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph
Marco Bronzini, Carlo Nicolini, Bruno Lepri, Jacopo Staiano, Andrea Passerini
Large Language Models (LLMs) demonstrate an impressive capacity to recall a vast range of factual knowledge. However, understanding their underlying reasoning and internal mechanisms in exploiting this knowledge remains a key research area. This work unveils the factual information an LLM represents internally for sentence-level claim verification. We propose an end-to-end framework to decode factual knowledge embedded in token representations from a vector space to a set of ground predicates, showing its layer-wise evolution using a dynamic knowledge graph. Our framework employs activation patching, a vector-level technique that alters a token representation during inference, to extract encoded knowledge. Accordingly, we neither rely on training nor external models. Using factual and common-sense claims from two claim verification datasets, we showcase interpretability analyses at local and global levels. The local analysis highlights entity centrality in LLM reasoning, from claim-related information and multi-hop reasoning to representation errors causing erroneous evaluation. On the other hand, the global reveals trends in the underlying evolution, such as word-based knowledge evolving into claim-related facts. By interpreting semantics from LLM latent representations and enabling graph-related analyses, this work enhances the understanding of the factual knowledge resolution process.
Read more8/7/2024
0
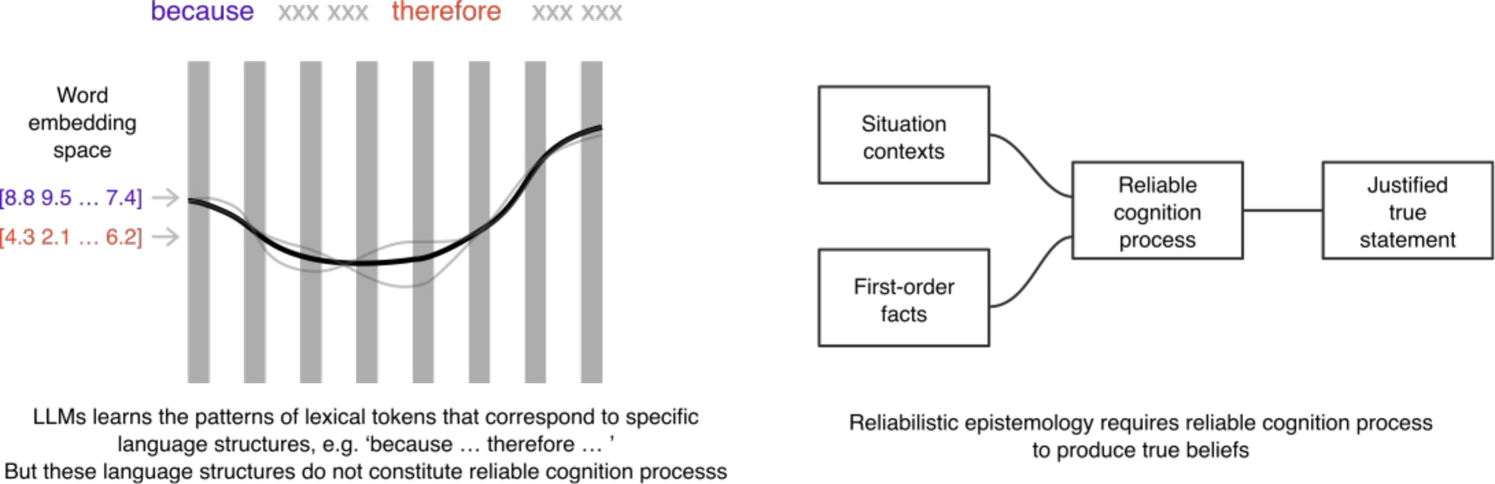
Misinforming LLMs: vulnerabilities, challenges and opportunities
Bo Zhou, Daniel Gei{ss}ler, Paul Lukowicz
Large Language Models (LLMs) have made significant advances in natural language processing, but their underlying mechanisms are often misunderstood. Despite exhibiting coherent answers and apparent reasoning behaviors, LLMs rely on statistical patterns in word embeddings rather than true cognitive processes. This leads to vulnerabilities such as hallucination and misinformation. The paper argues that current LLM architectures are inherently untrustworthy due to their reliance on correlations of sequential patterns of word embedding vectors. However, ongoing research into combining generative transformer-based models with fact bases and logic programming languages may lead to the development of trustworthy LLMs capable of generating statements based on given truth and explaining their self-reasoning process.
Read more8/6/2024

0
Large Language Model Enhanced Knowledge Representation Learning: A Survey
Xin Wang, Zirui Chen, Haofen Wang, Leong Hou U, Zhao Li, Wenbin Guo
The integration of Large Language Models (LLM) with Knowledge Representation Learning (KRL) signifies a significant advancement in the field of artificial intelligence (AI), enhancing the ability to capture and utilize both structure and textual information. Despite the increasing research on enhancing KRL with LLMs, a thorough survey that analyse processes of these enhanced models is conspicuously absent. Our survey addresses this by categorizing these models based on three distinct Transformer architectures, and by analyzing experimental data from various KRL downstream tasks to evaluate the strengths and weaknesses of each approach. Finally, we identify and explore potential future research directions in this emerging yet underexplored domain.
Read more7/19/2024

0
Unveiling Factual Recall Behaviors of Large Language Models through Knowledge Neurons
Yifei Wang, Yuheng Chen, Wanting Wen, Yu Sheng, Linjing Li, Daniel Dajun Zeng
In this paper, we investigate whether Large Language Models (LLMs) actively recall or retrieve their internal repositories of factual knowledge when faced with reasoning tasks. Through an analysis of LLMs' internal factual recall at each reasoning step via Knowledge Neurons, we reveal that LLMs fail to harness the critical factual associations under certain circumstances. Instead, they tend to opt for alternative, shortcut-like pathways to answer reasoning questions. By manually manipulating the recall process of parametric knowledge in LLMs, we demonstrate that enhancing this recall process directly improves reasoning performance whereas suppressing it leads to notable degradation. Furthermore, we assess the effect of Chain-of-Thought (CoT) prompting, a powerful technique for addressing complex reasoning tasks. Our findings indicate that CoT can intensify the recall of factual knowledge by encouraging LLMs to engage in orderly and reliable reasoning. Furthermore, we explored how contextual conflicts affect the retrieval of facts during the reasoning process to gain a comprehensive understanding of the factual recall behaviors of LLMs. Code and data will be available soon.
Read more8/14/2024